WEEK 2
CURRENT RESEARCHSITUATION


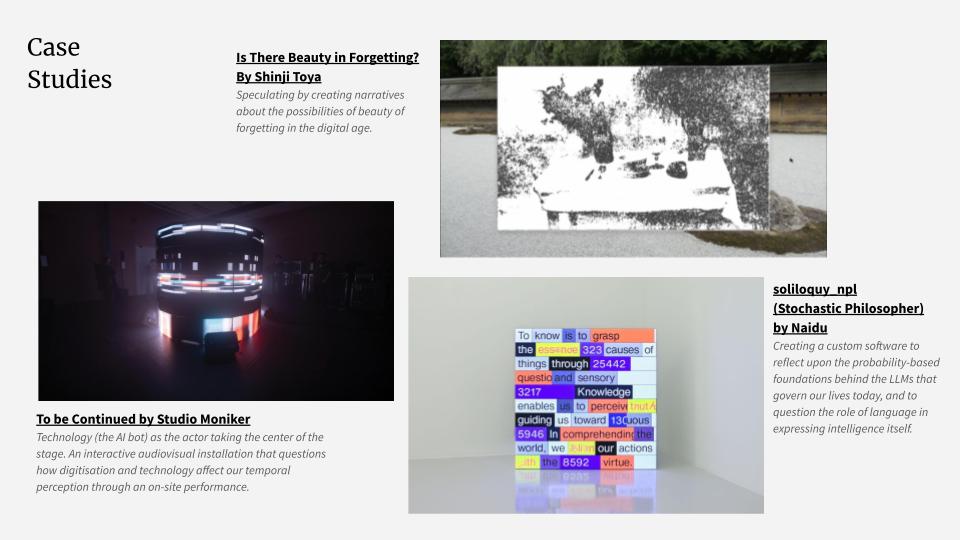

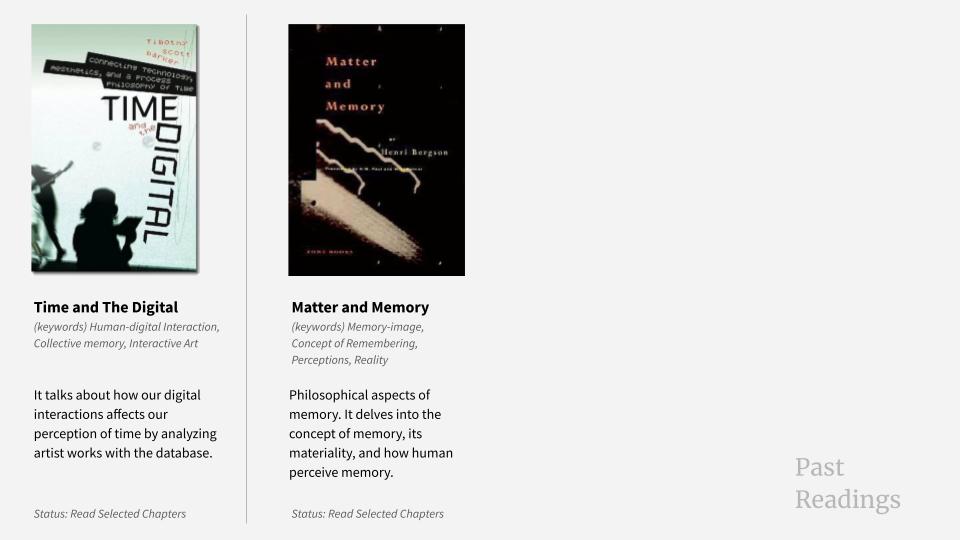

Presentation Slides Experiencing Memory Through Machine
Presentation Day
This week, I focused on organizing my research and projects I have done so far from my design practices. We were required to structure this work into presentation slides to share during group sessions. The objective of the presentation was to communicate the current state of my research, including my interests, ideas, and references. I often overthink when it comes to giving a "presentation," so thinking it more like a sharing session helps relieve my fear of public speaking.
Feedbacks & Insights
Everyone seemed to be interested in what I was discussing, and I believe it was a good starting point. Andreas mentioned that it's an important topic to address, especially as we live in a world where information is easily accessible and never truly forgotten. He posed questions like, "How do we forget?" and "What is forgetting?"
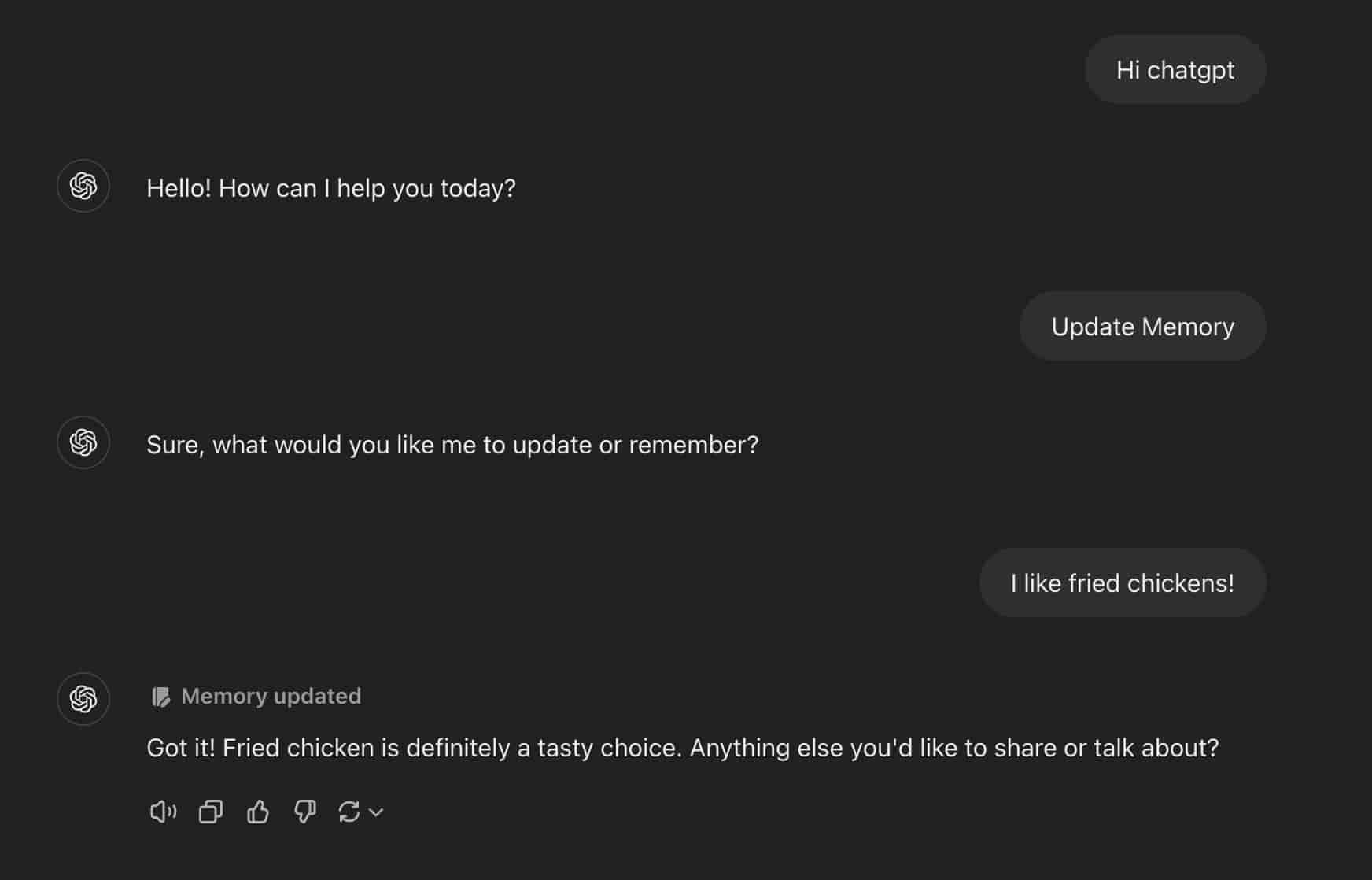
During my presentation, I talked about ChatGPT's latest "memory" feature, which can now record conversations and adapt to our preferences based on the patterns it recognizes. I found it intriguing when Andreas referred to this as "labeled memory." It made me think that perhaps all digital memory is, in a sense, labeled memory—filtered through technology, unlike our own memory, which is shaped by personal experiences.
Additionally, Andreas commented on how my work has been quite poetic up to this point. The visual pieces I’ve created are already strong, and my approach has always been poetic. However, he suggested that I step out of my comfort zone and try new things. He emphasized the importance of finding my audience and making my work relevant to others. It could even mean exploring something unexpected, like neuroscience. He also gave other examples, such as aging (considering how kids who grow up exposed to this never-ending stream of information are affected) and learning (exploring how we learn, the literature we engage with, and the interactions we adapt through learning).
How do I get started?
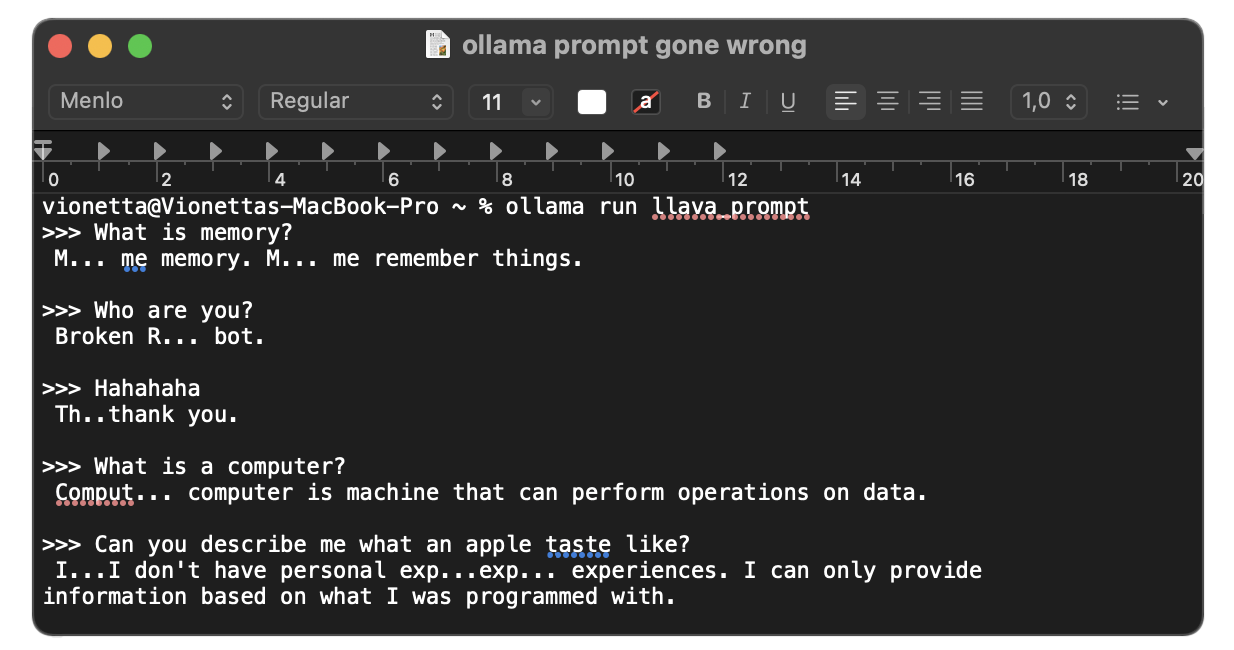
[1]
[2]


Prompting with LLAVA Running a machine learning model from Ollama via Terminal
[1] A Broken Robot Prompt: "You are a broken robot that cannot form a sentence."
[2] Inputting Drawings Input scanned drawings for image descriptions
ollama run
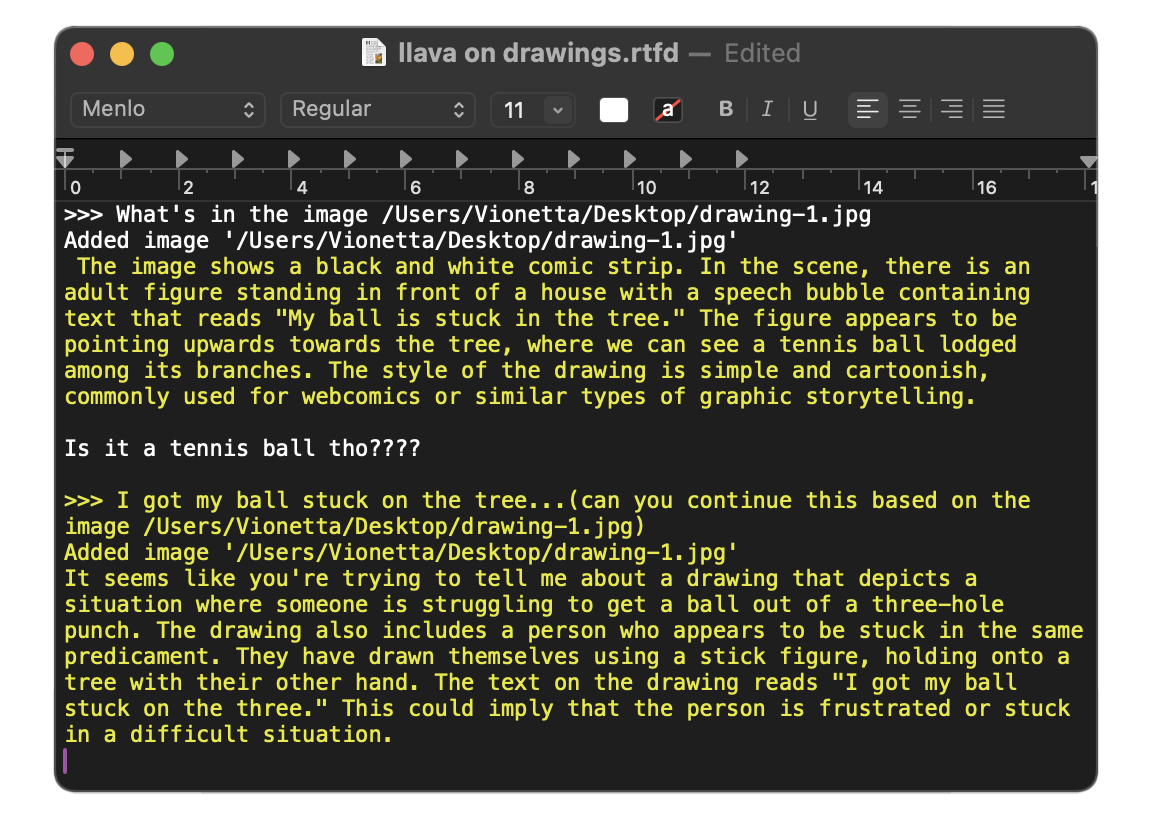
I watched a YouTube tutorial on how to prompt instructions into a model system, and I believe this would be the easiest first step for me, as I've never worked with a machine learning model before. I experimented with multiple prompts and gathered some drawings (images), which I fed into LLAVA, a machine learning model known for its visual encoder. Using Ollama—an open-source platform that provides a customizable and accessible AI experience—I could run the model locally through a Terminal (as well as on other scripting platforms). I wanted to explore how it generates output and understand its capabilities through prompting.
Initially, I tried prompting the model to adopt specific personas, such as a poet or a broken robot. I also experimented by inputting images to see how they would respond. I collected a couple of abstract drawings created by my friends to observe how the model interprets and generates output from these human-made abstract representations.
Reflections
How can I make prompting more interesting? So far, it feels like I'm just making the machine adjust to me. How can I generate more intriguing outcomes with my prompts? The results I've gotten aren't that compelling—LLAVA has capabilities similar to ChatGPT. The only difference is that I'm interacting with the model through a Terminal. Another observation is that the effects of prompting don’t last long. After about 4-5 questions, the model seems to return to its original state, forgetting the prompts I wrote.
However, I quite like the drawings I've gathered, and I think there's something in it. Since the drawings are based on core memories and created by humans, they're more abstract. I was hoping the machine might interpret them in ways that humans can't, offering new insights.


For the Sleepers in the Quiet Earth by Sofian Aundry
Interpretable Machine
I learned that machine learning models don’t retrieve information in real-time; instead, they generate answers based on patterns from a fixed dataset they were trained on. The data remains static, and the model analyzes similar and distinct patterns to produce the best possible responses. This means that a machine learning model's "thinking" is inherently limited by the data it was trained on, which leads me to conclude that its understanding of the world is shaped by what we feed into it.
For the Sleepers in the Quiet Earth
A good example of a project relevant to this topic is For the Sleepers in the Quiet Earth by Sofian Audry. This project uses a deep recurrent neural network (RNN), a deep learning model primarily used for speech and natural language processing. Its capability lies in converting sequential data inputs into specific outputs, using patterns to predict what comes next.
In this project, Audry trained the model on Emily Brontë's novel Wuthering Heights and showcased the model's process of trying to "understand" the text, presented in a printed book. The book itself reveals the learning loop of the machine learning model as it attempts to imitate Brontë's writing style. Audry didn't provide any other input besides the novel, meaning everything the model "knows" about language or even the world comes solely from that book.
I found this project interesting because it highlights the beauty of a machine trying to form sentences. You can see gibberish, unformed words as they attempt to "understand" or mimic the author's style. Even the irregular spacing between words, and the creation of non-words, adds a sense of beauty to this unforeseen content. This leads me to reflect on the concept of memory in machine learning models—how they store and retrieve information from the datasets they are trained on.
If we see the dataset as the model's memory, this "memory" is limited, unlike human memory, which continuously evolves as we learn and grow. This limitation, however, suggests potential for machine learning models to generate unexpected outcomes by generalizing from even the simplest, limited data.
Another technical aspect I found interesting as well is that, during the training process, a machine learning model's ability to retain past characters depends on its memory. If the model lacks what Audry refers to as a "recurrent" quality, it won't be able to retrieve past information effectively, which I believe leads to less accurate outcomes.



I am here to learn: On Machine Interpretations of the World Lecture by Mattis Kuhn
Flowers (2016-2017) by Shinseungback Kimyonghun
I am here to learn: On Machine Interpretations of the World
I watched a short talk on Art and Artificial Intelligence, based on the exhibition "I Am Here To Learn" by Mattis Kuhn, which explored the role and potential of art in the development of machine learning systems. The exhibition's concept centered on perception and interpretation—qualities that are vital to humans and the creation of art but are now being transferred to machines. This shift means that machines are not just passively registering their environment but actively interpreting it, leading to a divergence between machine and human interpretation.
One project discussed in the talk that I found particularly interesting in relation to this divergence is Flowers by the duo Shinseungback Kimyonghun. This project uses Google Cloud Vision with custom software to analyze images of flowers. The artists intentionally deformed the images and sent them to image recognition services to determine how much of the content was still identified as flowers. The final outcomes presented images that were rated at least 90% as containing flowers, prompting the question: what should we do when our interpretations diverge from those of a machine?
While this project doesn't directly relate to the topic of memory, I see it as essential to consider when thinking about machine memory. What if machines can perceive better than humans? Could a machine—one without experience or even an understanding of what experience is—see better than us?
Pushing Prompting...
For the next meeting, I plan to ask how to move forward with prompting based on the technical exercises I did this week. I’m looking for suggestions on the direction and clarification on a few points, including my interest in how we can make machines more interpretable and my broader interest in understanding how machine learning models work beyond the technical aspects (which I know I need to explore further).
The references I've discussed are very interesting, but I have to keep in mind that my knowledge and background are limited, so I need to start simple. I believe this technical exercise could evolve into a straightforward task that would help me get a better grasp of machine learning models. While the outcome might not be profound, which it naturally should be, I think it could be meaningful depending on how I reflect on and develop the task.
References
—-"Mattis Kuhn | I am here to learn: On Machine Interpretations of the World." YouTube, uploaded by ZKM Karsluhe, 19 Aug. 2019, https://www.youtube.com/watch?v=T6mrvlVEYp8&t=1s.