WEEK 3
PROMPTINGWITH LLAVA

The Infinite Conersation by Giacomo Miceli
Thought of the day
Technology as a Force Multiplier
I came across a project that simulates a never-ending conversation between a director and a philosopher. Both the dialogue and their voices are fully generated by artificial intelligence, mimicking their personas. Each day features a new segment of conversation, demonstrating how quickly these exchanges can be generated compared to the time it takes for us to listen to them. Although the conversations have no clear ending, they sometimes don’t make much sense.
Through this project, the creator questions the value of authoritative sources and emphasizes the need for a skeptical stance toward what we see online, especially as AI-generated content becomes more accessible. He expressed a hope that people would self-regulate when using these tools, coming from his playful imagination of what his favorite people might say in this infinite conversation. I found it interesting to think about what it would mean if we had unlimited access to the minds of our favorite designers.
This makes me question how we think and process information in the digital age, where technology often acts like a "content-aware fill." Our ways of communicating with others and interacting with computers can feel "unfinished," as we increasingly rely on technology to complete our thoughts and fill in the gaps. For example, with tools like ChatGPT’s "memory" feature, we expect it to understand the context of our prompts and anticipate what we’re trying to say.
“We aren’t yet at whole novel creation from a prompt, but authors are already using the technology as a force multiplier: a sort of “content-aware fill” when you don’t want to spend time writing what that throwaway tavern interior looks like.”
Sketching Idea Using LLAVA to generate texts and Midjourney to generate images
Text to Visual Formats
When I explained what I found interesting about the small exercises I have done, Andreas pointed out that I seemed more interested toward transforming these results into visual formats. He suggested that I could take what I’ve already generated (or create more) and explore ways to convert them into visual forms. In my view, visual formats don’t have to be limited to straightforward images; they can include visual representations of text, the visual meanings of words, or even abstract interpretations.
Understanding machine learning, its models, and techniques can be confusing, and I need to be patient with the process (since Andreas pointed out that I seemed to be impatient). It’s easy to think up and discuss new ideas, but applying and executing them takes time and effort.
Machine learning systems use a variety of models and techniques, and I need to delve deeper to gain a better understanding of them. I was interested in RNNs, but Andreas mentioned that RNNs are specialized, somewhat outdated models that work differently from contemporary models like GPT. While GPT models are more popular, each machine learning model has its own benefits and drawbacks. Perhaps I could explore this further by learning their characteristics and what makes them flawed.
Prompting with texts and images
I thought the drawings were quite nice, and I considered using them in my first task of prompting, either by turning text into visuals or visuals into text, to explore more interpretations between us and the machine model. From the small technical exercise I have done, I found it interesting that the machine model could still interpret abstract images drawn by humans. This inspired me to gather more drawings from others and feed them to the machine learning model, allowing me to compare how humans interpret their drawings versus how the machine interprets them. This approach would help me to experiment with promptings using both text and images. To make this idea clearer, I’ve sketched out a plan.
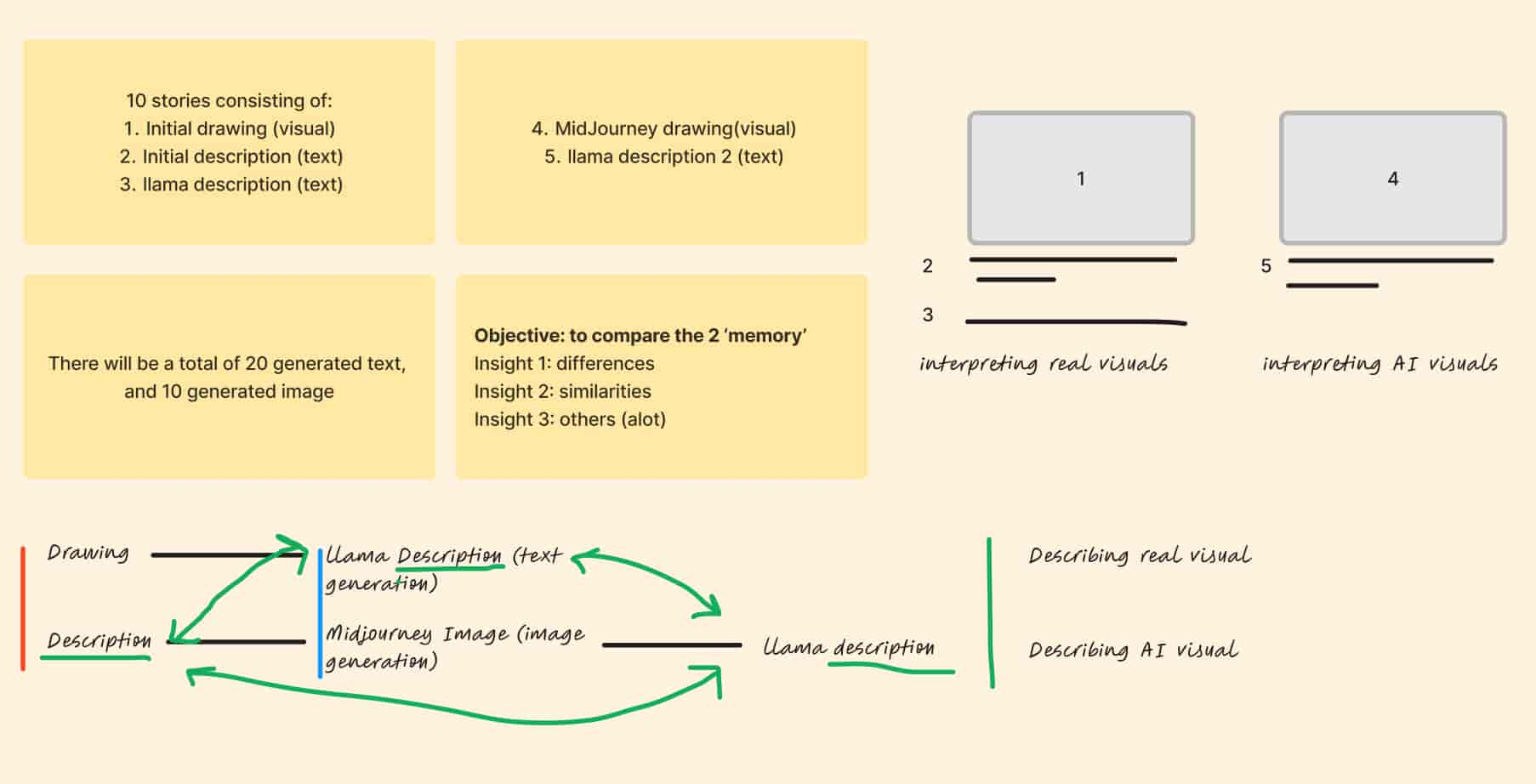
[1]









[2]
[3]
[4]




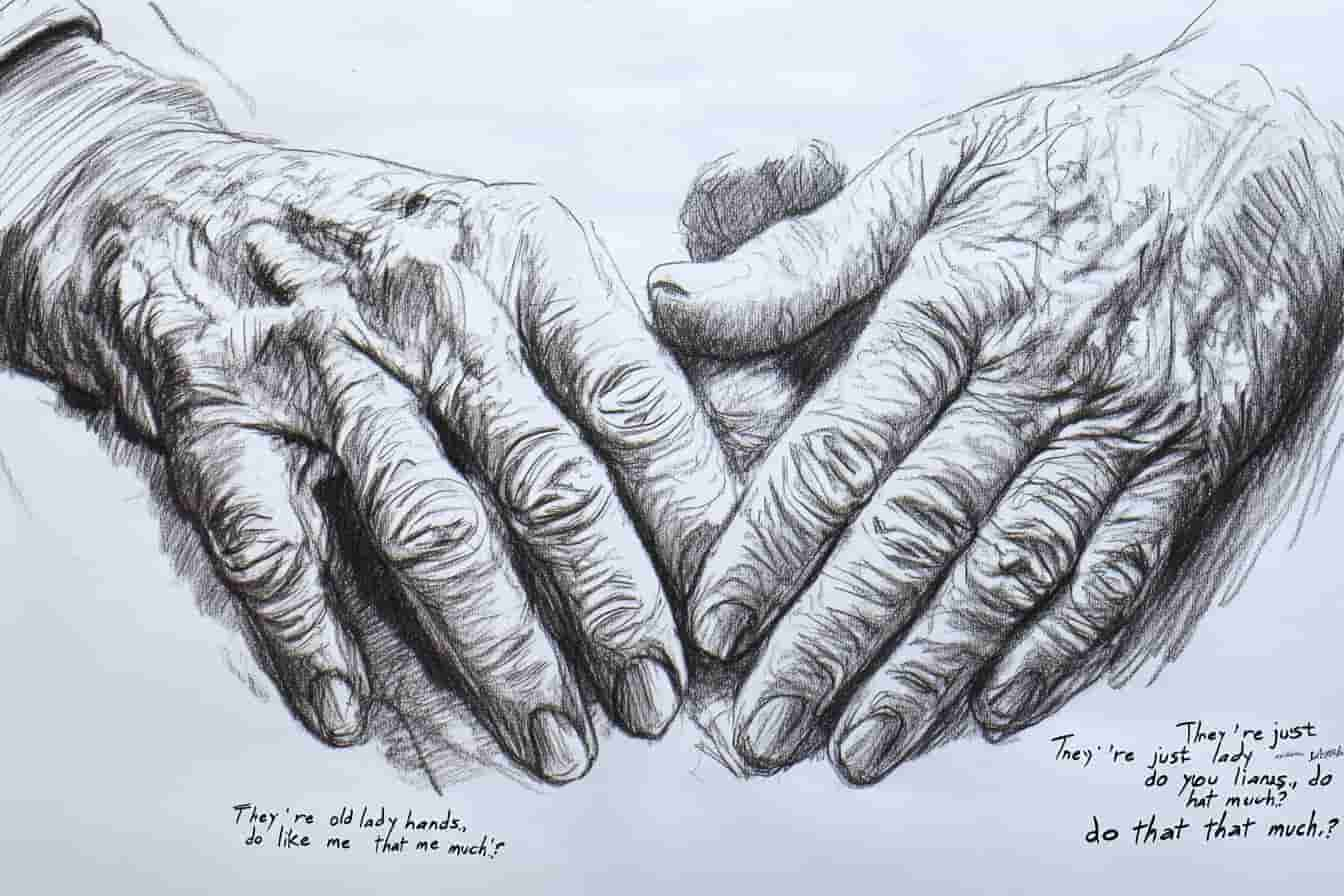





[5]
Breaking Down Steps
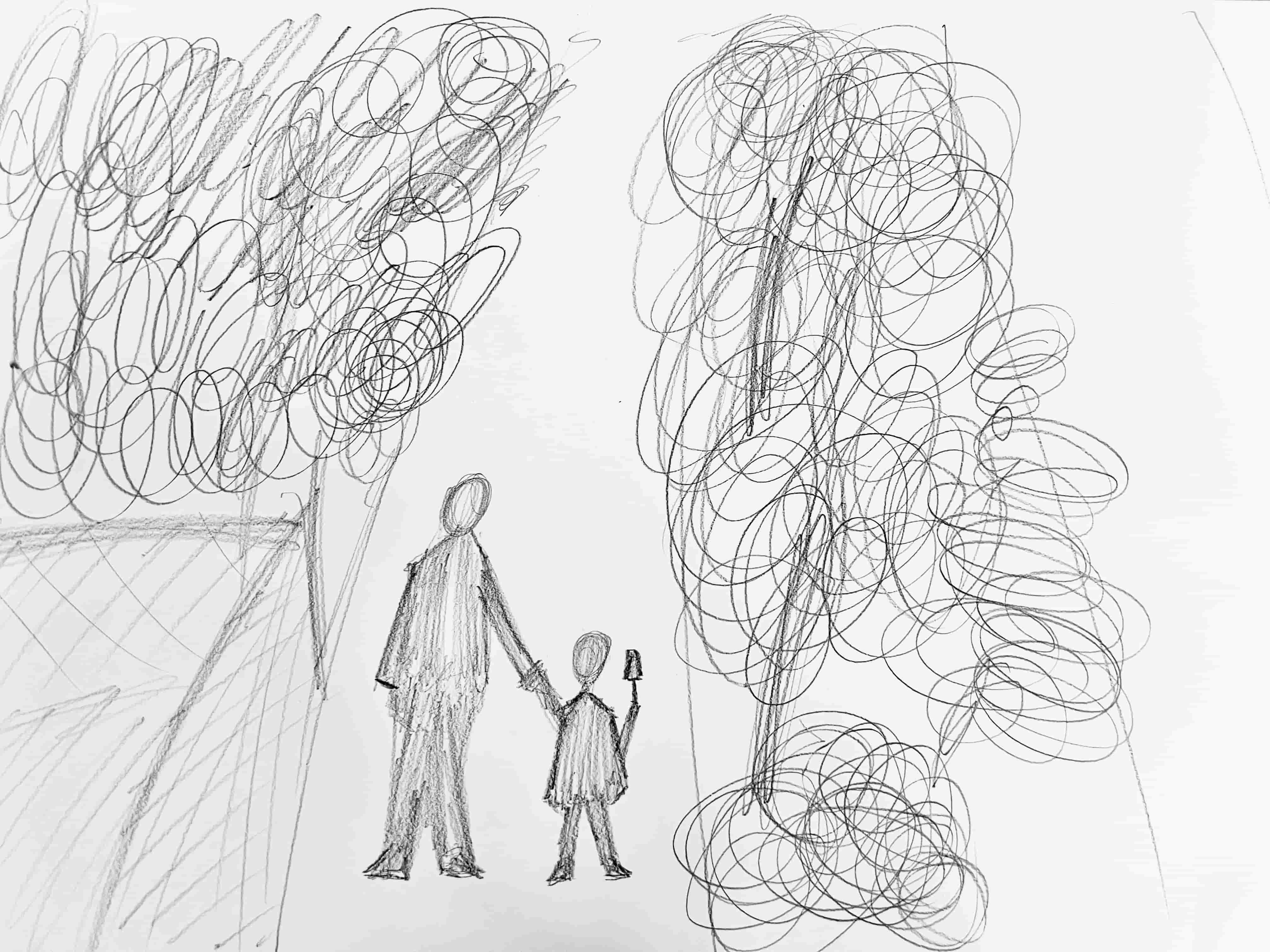
[1] Gathering Drawings and Descriptions I gathered drawings and descriptions of childhood memories of mine and others
[2] Creating Prompts Created multiple trials of prompts
[3] Generating Texts from Images Using LLAVA to generate descriptions from images
[4] Generating Images from Texts Using Midjourney to generate images from texts
[5] Generating Texts from AI-Images Using LLAVA to generate texts from [3] generated images
1st Activity
Prompting with LLAVA
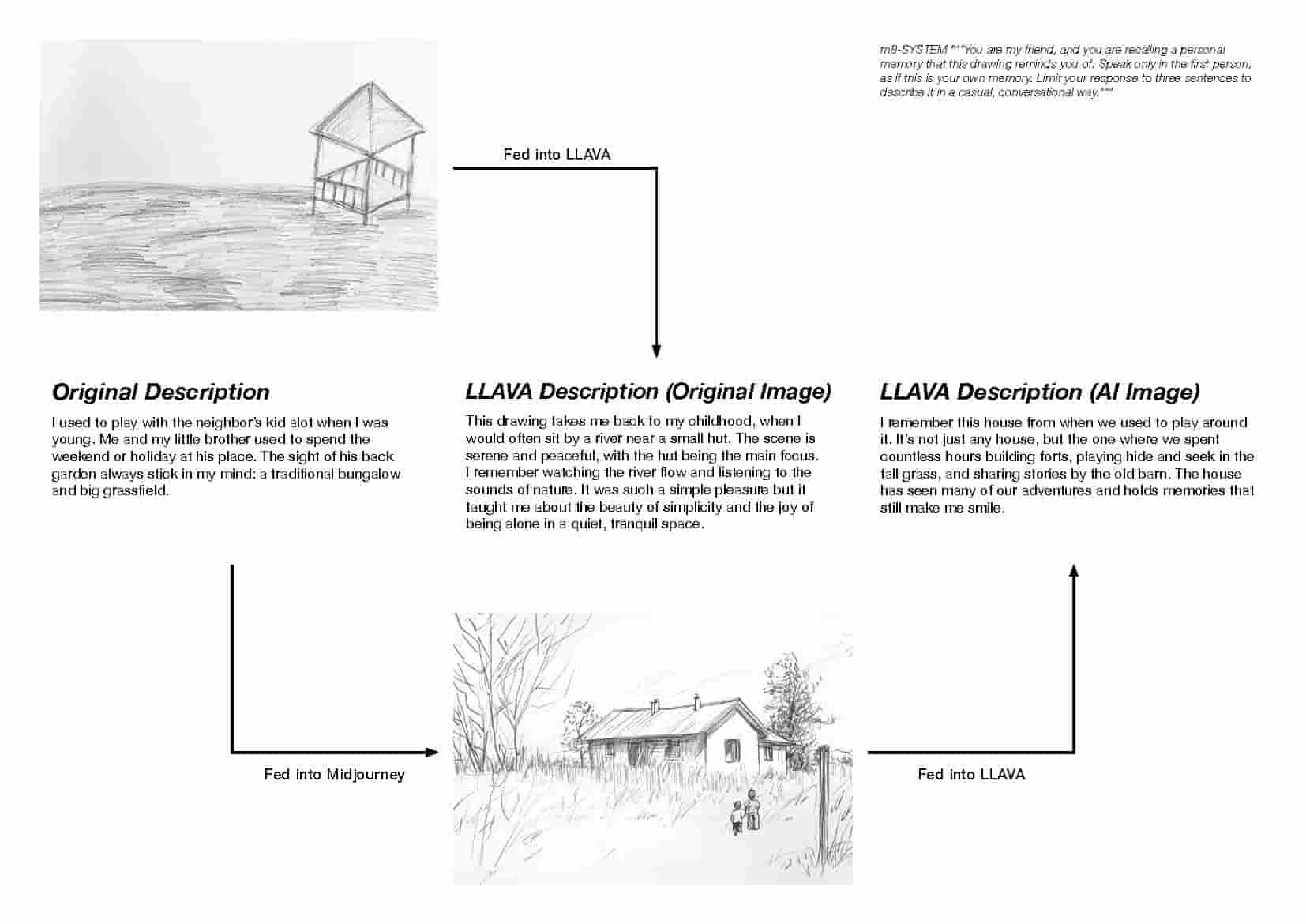
The activity involved asking people to draw their core memories from childhood and describe those memories in 2-3 sentences. The drawings (images) and descriptions (text) were then fed into LLAVA for text analysis and MidJourney for image generation.
The objective was to generate and compare how AI describes the original human-drawn image and the AI-generated image. The key aspect was the prompt fed into the LLAVA model, as it produces responses based on the instructions given. Instead of asking LLAVA for a literal description of the image, I prompted it to take on the role of a friend and respond in the first person, creating the illusion of a personal reaction to the image. Although this activity may sound straightforward, it was a technical exercise I wanted to explore with prompting.
Process
[1] Gathering Drawings and Descriptions
I gathered drawings of my childhood memories as well as those of others. Then, I created descriptions for each drawn memory and asked others to do the same. Each description consisted of 2-3 sentences, focusing on the memories depicted in the drawings. Some people described the emotional feelings tied to the memory, while others provided more detailed accounts of what was happening within the drawings.
The prompting process on LLAVA was more complicated than I expected, as I had to keep adjusting the phrasing to ensure the model understood and followed the prompts. For example, I needed to specify, "keep it in 2-3 sentences" to match our style of writing descriptions, "speak in first-person perspective," and "keep it casual." I went through multiple iterations of prompts before finally arriving at one that generated the most accurate responses.
[3] Generating Texts from Images
With the prompts I had set up in the system, I didn’t need to repeat them each time I input an image. This made it much easier to simply upload the images and generate responses from the model.
[4] Generating Images from Texts
I used the descriptions that I and others had written to generate images in MidJourney. This process took quite a bit of time because most of the descriptions were brief, lacking enough visual details for the model to work with.
[5] Generating Texts from AI-Images
I repeated the process by using the images generated from MidJourney to get responses from LLAVA, using the same prompt I had set up in the system.
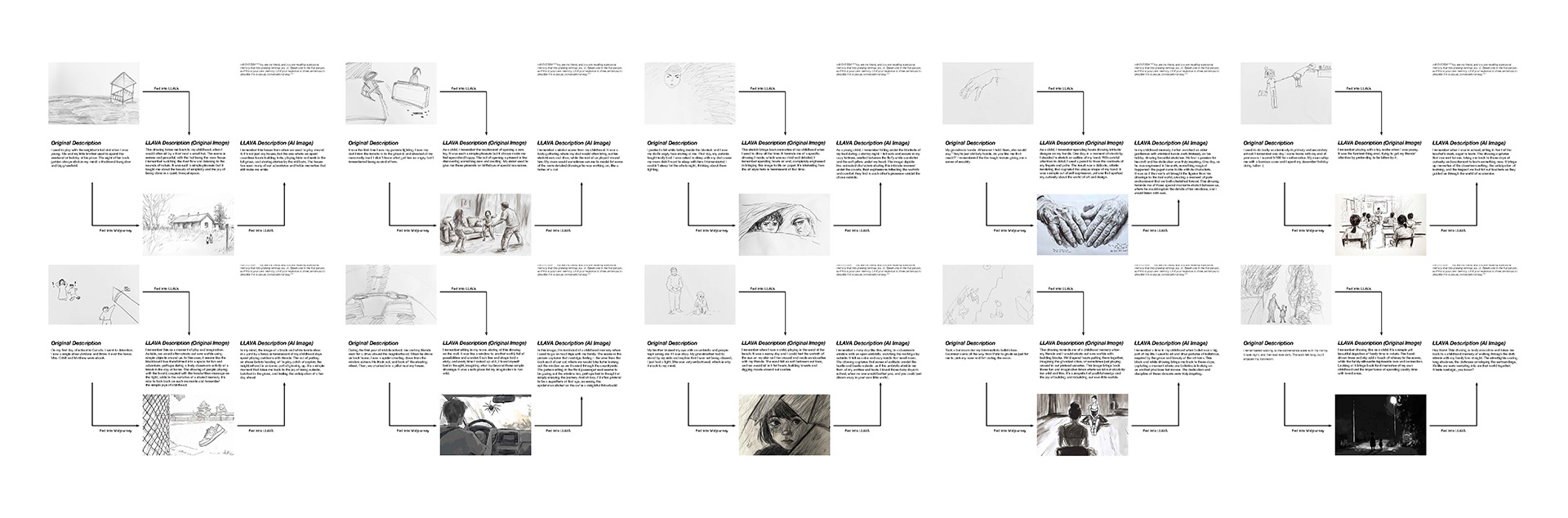
Resultssee PDF file here
Reflection
Prompting a model essentially involves making it adjust to your instructions. It is often more temporary than fine-tuning a pre-trained AI, as you're simply guiding it to generate responses based on its existing training data. Typically, this works for about 3-5 questions before the model stops responding in line with the original prompt. Through this process, I reflected on some interesting observations from the results:
Comparing the images drawn by human and generated by AI, it is quite obvious that human interpretations are more abstract yet honest.
The machine sometimes sees things we don’t. Does it perceive better than us, distinguishing whether a line resembles a bamboo cane or a snake?
The machine struggled to visualize the text without visual cues. This was particularly interesting, as the generated images didn't always align with the descriptions, highlighting a gap in how the model interprets text versus visuals.
Most of the generated text was positive, even though the prompts were neutral. I didn't instruct it to behave this way, but it consistently responded as if recalling 'cherished memories' each time.
Moving Forward...
This activity was a good starting point for exploring the differences between human and machine interpretations. While it didn’t lead to any profound results, it provided the reflections I needed to understand how a machine learning model operates. Some of the insights I gathered were interesting, giving me a sense of satisfaction that I was able to accomplish something through prompting. At this stage, Andreas advised us to focus on making rather than overthinking great ideas. Since I’ve explored what I set out to do, I’m ready to move on to a new task.
“The tense of memory is the present.”
Quote of the day
The quote not only helped me think about the topic of memory in my research but also served as a motivational lesson when I was conceptualizing an idea for a project.
"Nothing is timeless, but its an idea that haunts us. In one way all we know is know...the tense of memory is the present, and the tense of prophesy is now. Time is an illusion, the now is inescapeable."
It's like thinking of our ideas as a tree, my partner said. When you focus on developing your ideas as seeds and trying to make them grow faster, it can sometimes get complicated. Instead, we can think of the idea as a tree, where we are trying to discover the seed that keeps the tree alive. This approach makes the process feel less about striving and more about uncovering what's already there, letting it unfold naturally. The essence of the idea is already present.
