WEEK 6
QUANTIFYING IMAGE
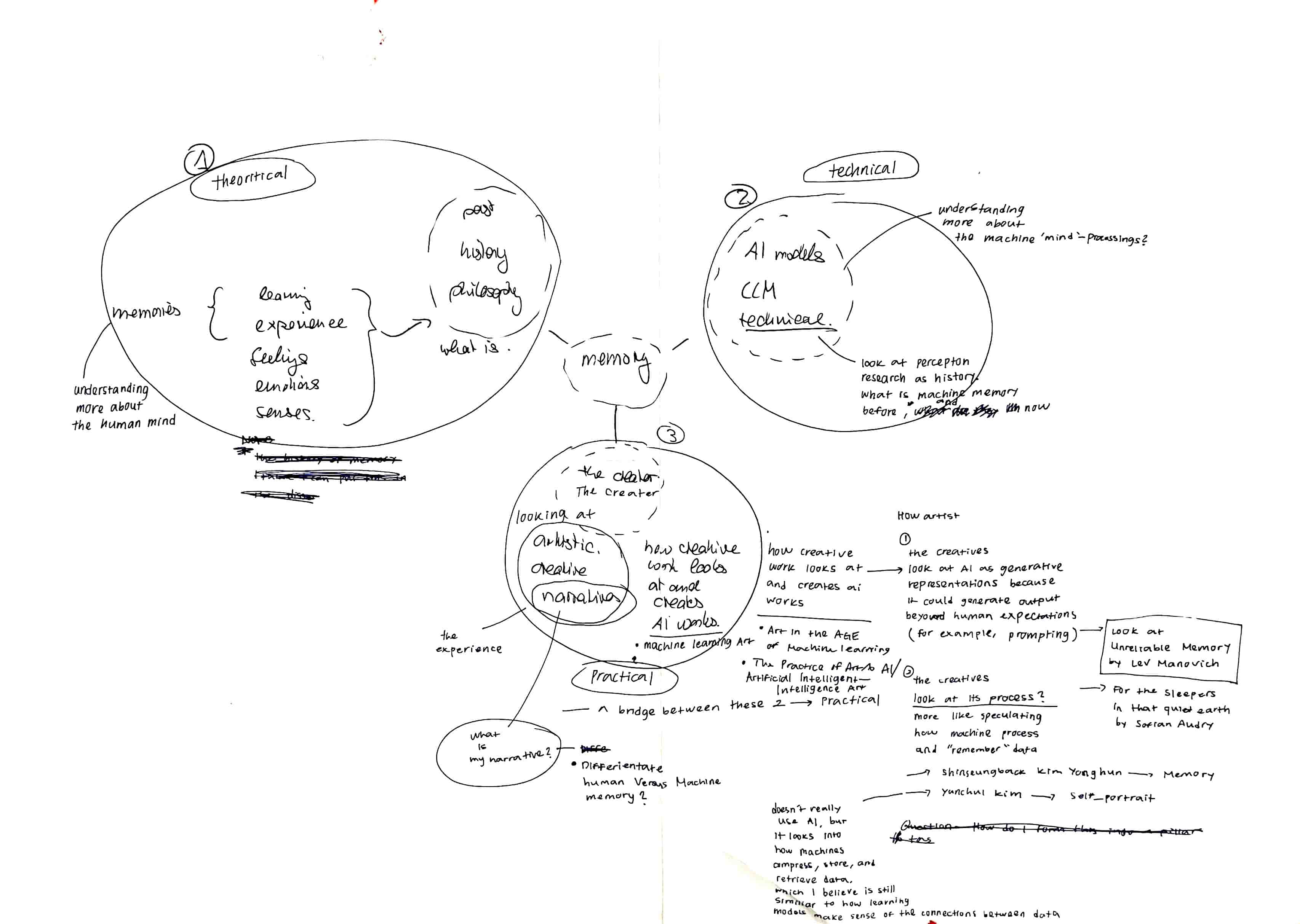
Mind Map 3 pillars for my literature review
3 Pillars Defined
After some reading, I've decided to base my three pillars on three aspects: theoretical, technical, and practical. These aspects will help me better understand what memory means for humans (theoretical) and what machine memory is (technical) to create a comparison between human and machine memory. The third pillar will focus on how creatives use and look at these machines for artistic expression, connecting back to my research practice. Overall, these three pillars will serve as a foundation to connect and synthesize my readings.
1. What is Memory?
2. What is Memory to a Machine?
3. What is Machine Learning to Humans?

Self_portrait.jpg by Yunchul Kim
Transcibing Image
I decided to give myself another task after looking at Yunchul Kim's work. In this project, Kim transcribes his self-portrait using letters, numbers, and special ASCII characters. When these characters are processed by a computer, they recreate the artist's self-portrait. Through this project, Kim examines the relationship between humans and machines.
Could there be an analogy between the memory format of a human brain and an automated system since both need to convert physical impressions into storable information?
He explores this question by creating a representation that is readable by both humans and machines, asking, “Could this self-portrait also be an attempt to depict a self-portrait on the level of a cerebral representation of one’s own image?”
Documentation Printed and Digital Outcomes
Experiments
Quantifying Image
In this experiment, I encoded an image from my personal digital gallery by extracting its RGB values. Using p5.js, I created a code to perform this encoding and then fed the resulting RGB values to ChatGPT to see if it could visualize the original image based solely on these values.
The objective was to quantify something inherently unquantifiable—memories. For me, the image represents childhood memories; for the machine, it’s merely numerical data in RGB format.
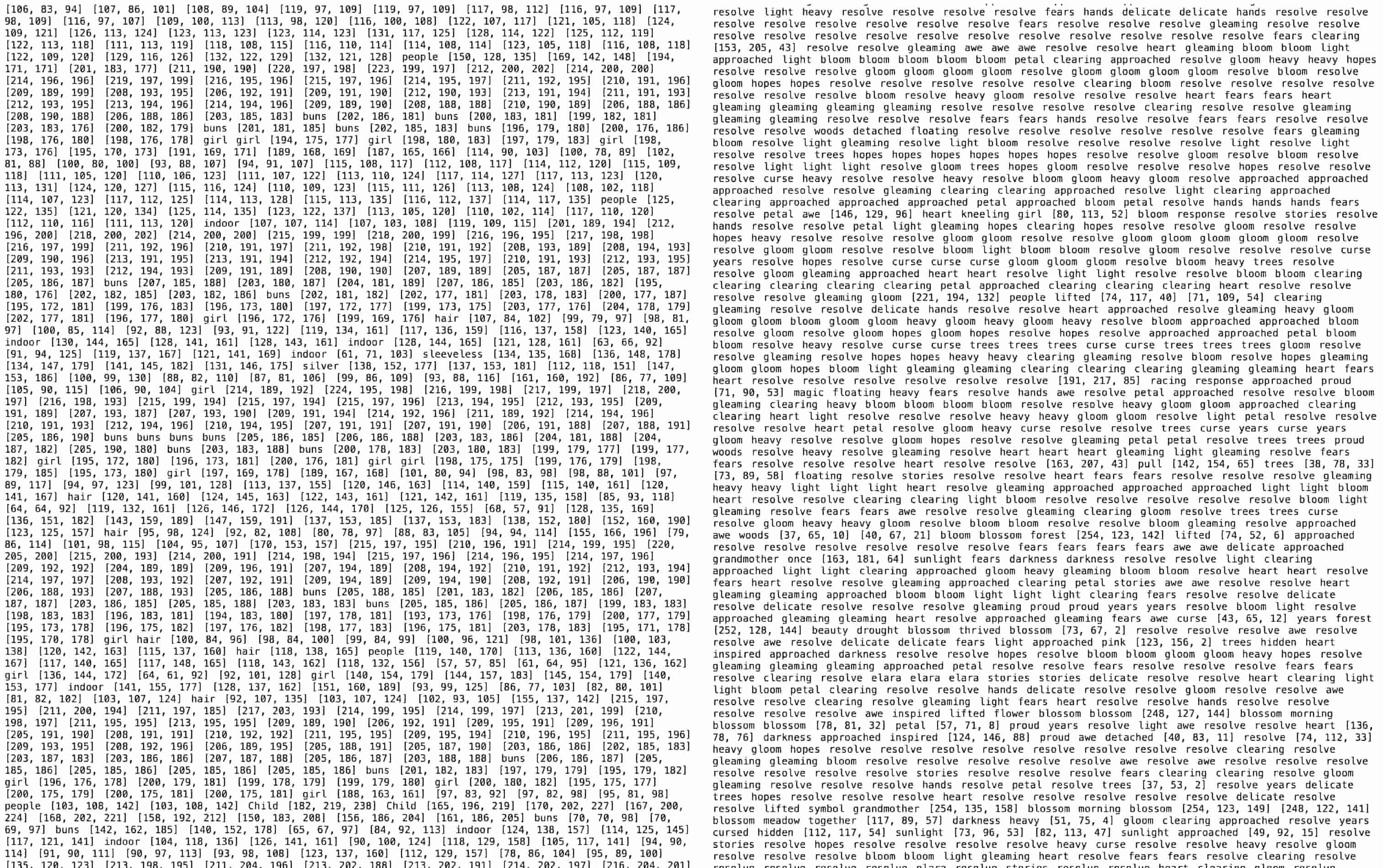
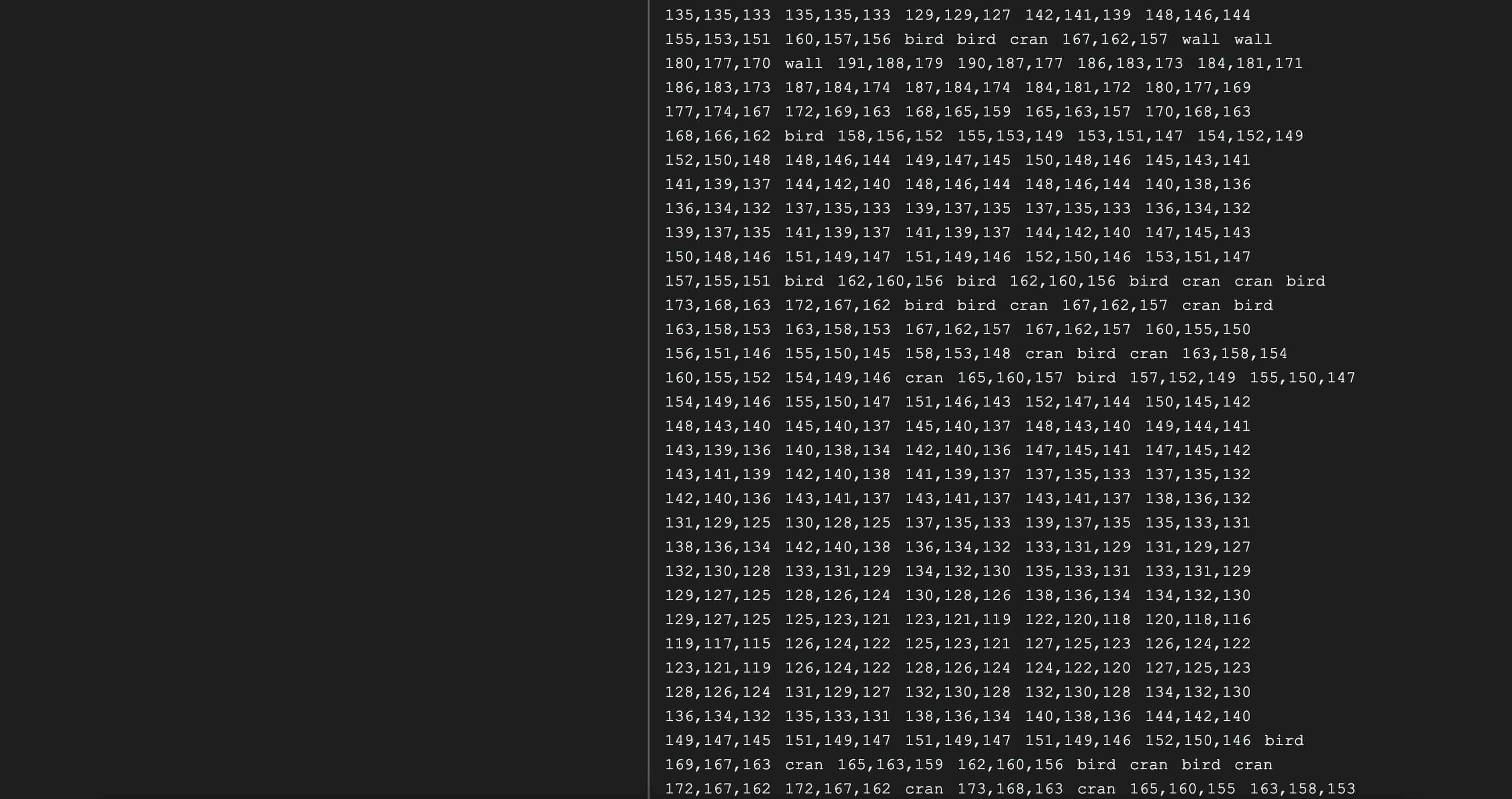
In a further experiment, I also tried matching these numbers with words derived from ASCII character values. The resulting output became more poetic, combining numbers with descriptive words that hint at the images.
For me, this experiment relates to memory as it explores what is invisible to us through machines, emphasizing how our perception of memories differs. For humans, a memory (like a moment captured in a photograph) brings to mind abstract sensations, such as a smell, color, and sound; whereas, a machine recalls specific, quantifiable details—exact times, dates, locations. This simply shows how fundamentally different we are in this regard.
I realized that the issue with the previous task of prompting with LLAVA was that I was trying to make the machine “think” or “act” like a human. This experiment, however, tries to show that there is beauty in how a computer or machine processes information in its own way.

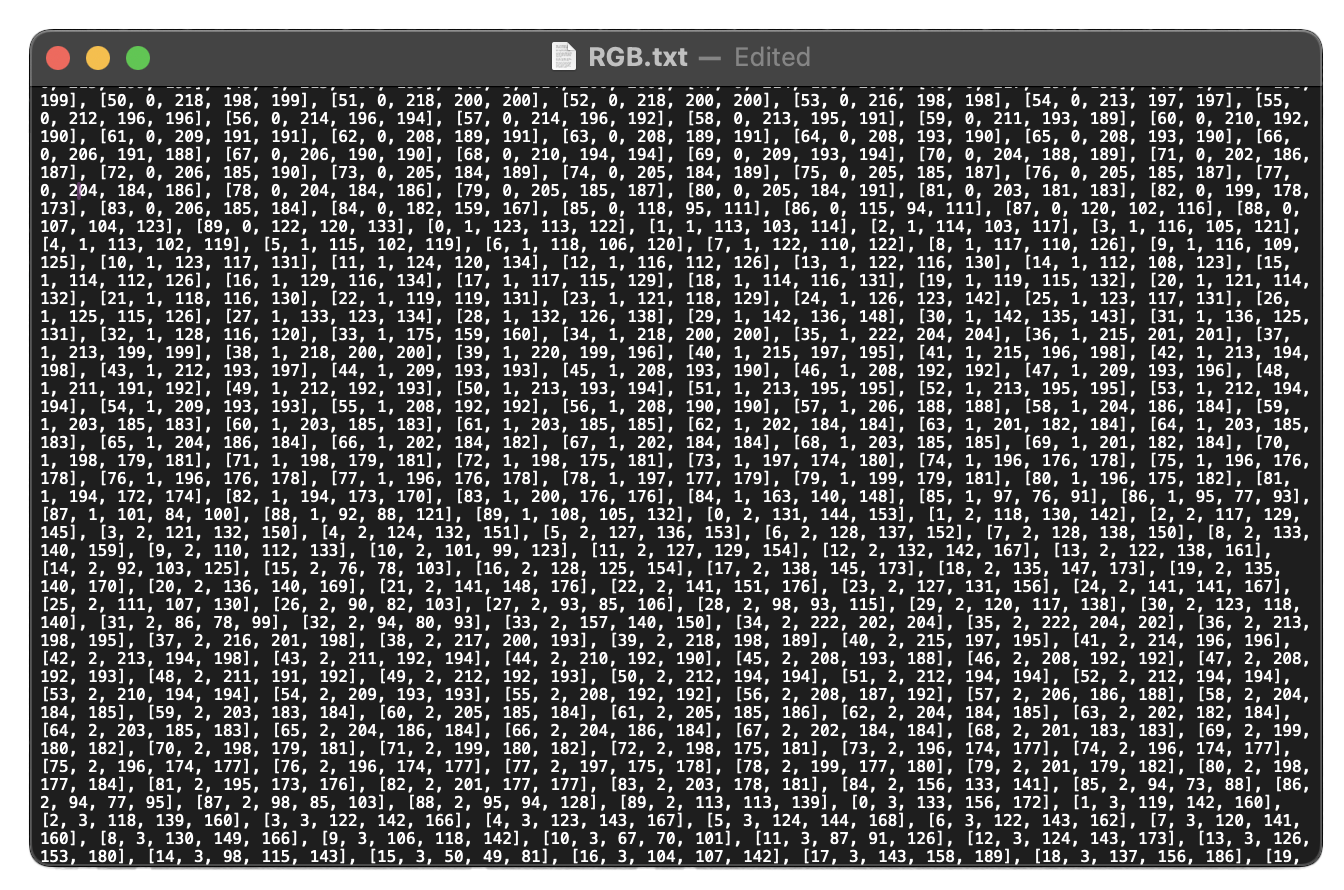
Extracted RGB Values See PDF file
1. Extracting the RGB values of an image
RGB Values
Yunchul's Self Portrait inspired me to take on this little experiment of encoding images by its RGB values. I chose RGB values because it’s a simple, foundational method for image encoding and provides an easy way to understand how an image is represented as data in computer memory.
I started by extracting data from various images to see the character count generated by different image dimensions. I was surprised to find that even a compressed 90x70-pixel image—similar in size to a favicon—produced over 50,000 characters. This led me to think about the vast amount of characters are there in my digital gallery, with all those uncompressed snapshots and buried screenshots, It's crazy to think how much characters the computer system could handle at the same time.
When I tried to print these characters on the paper, I had to shrink the font size just to fit a manageable number of pages. Without resizing, a single image would generate over 150 pages of characters! This made me think about a silly idea, what if I just submit these papers as a photography project, would it still consider an image if these numbers scanned by a computer result to an image? It was just a funny thought that I would like to express.
Ladder by Everest Pipkin
2. Manipulating the RGB values by adding text
RGB + ASCII Values
After getting the RGB values, I fed them into ChatGPT to see if it could interpret the data and visualize the original image. I was surprised that it managed to recreate the entire image using just the numbers I provided. This led me to try an additional experiment where I incorporated words by converting the values to ASCII characters. If a word matched an RGB value, it replaced the number with the corresponding word.
This technique used in the additional experiment was inspired by Ladder by Everest Pipkin, as part of the NaNoGenMo. In this project, she reveals the mushy inside of file encoding. She uses node.js to access the file directory, providing one file for text, and the other for the binary numbers.
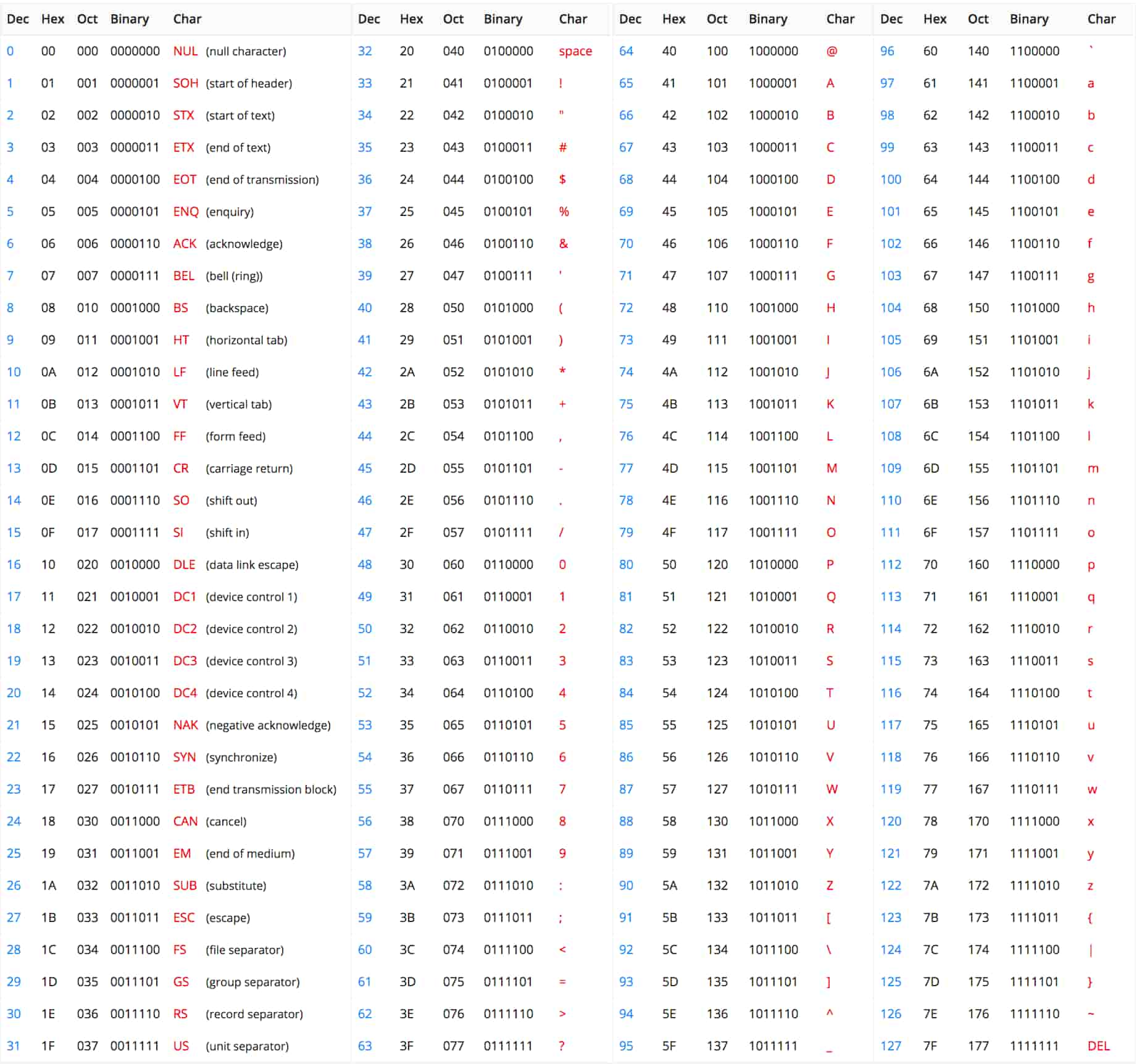
ASCII Table Each character is assigned a unique 7-bit code
charCodeAt(k)
I used this function to convert each word into specific values based on ASCII codes as a standardized method. In the p5.js code, this function calculates a "word sum" by summing the ASCII values of each character in a word. Since I needed to match these values with the RGB values, I normalized the range to 0-255 (the RGB range), rather than the standard ASCII range of 0-127 (as shown in the table).
let normalizedWordSum = wordSum % 256;
To keep the word sum within the RGB value range (0-255), the code uses wordSum % 256. This operation takes the remainder of wordSum divided by 256, effectively "wrapping" the sum to fit within 0-255. For example, if wordSum is 300, 300 % 256 equals 44, making 44 the normalized word sum.
P5js SketchRGB + ASCII values
Check out the sketch to see the full code
Initial sketch is extracting the RGB values
Upload your Image and create your own poem
Website
Poem With Numbers
I created a website where people can create their own poems using images. They can upload any image and write words or sentences that describe it, and the site generates an output similar to mine. People can also download the output as text file if they want to keep the poem. It's a fun way for others to create poems using pixel data!

A2 Printed Outcomes See the PDF file here
Prints
I printed both outcomes (my childhood image and flower image) onto a large A2 sheet of paper, setting the font size to 4.2pt (the maximum I could set to fit the page). Copying and pasting so many characters into the Illustrator artboard was actually quite challenging—I had a rough time with my computer repeatedly force quitting the software.
Actually, if I had more time and resources, I’d love to print these characters on a long sheet of paper, like receipt paper or scrolls. If it was possible as well, I imagined scanning them directly into the computer to create the original image from this pixel data.


1st Try


2nd Try


3rd Try
ChatGPT's Generated Inputting the txt file to create images with ChatGPT
3. Inputting the pixel data to ChatGPT
ChatGPT Visualization
The final step was to feed the manipulated data into ChatGPT for another visualization. I wanted to see if it could still recreate the image from the manipulated data I had collected.
From the results, it seems that there were some issues with the code, as ChatGPT couldn’t determine the correct dimensions of the image based on the number of extracted RGB values. The first attempt didn’t work well, and in the second try, I was more specific, explaining that the data was manipulated and converted into ASCII values. This attempt seemed closer to capturing the original image, but the final try still didn’t quite work, with a lot of red pixels and several errors.

Image Segmentation A technique in machine learning
Feedbacks & Insights
This experiment is a good starting point for exploring what machines "see" by using RGB values to quantify images. The images I used here could be seen as representations of memory, prompting questions about how machines like computers or machine learning models interpret subjects.
Andreas suggested me to look into image segmentation, a technique that classifies images based on color maps. There are various types of segmentation, many of which are important in machine learning tasks like object recognition, image analysis, and background removal. Moving forward, I could explore how machine learning uses algorithms to measure and perform certain tasks, transitioning from exploring pixel-based measurement to algorithm-based measurement.
In computer vision, pixel-based measurement is straightforward and effective for simple tasks, such as detecting brightness, contrast, or edges. However, it lacks the ability to understand context or patterns. Algorithm-based measurement, on the other hand, uses machine learning or advanced techniques to extract complex features and patterns, enabling tasks like object detection, segmentation, and recognition for a deeper, more abstract understanding of images.
Another area Andreas mentioned, which I haven’t explored yet, is how our brains simulate responses to stimuli. For example, brain scan activity can be used to visualize images we see, which is a more scary concept to me—it’s like creating a superpower to read minds.