
WEEK 2
DAYDREAMING
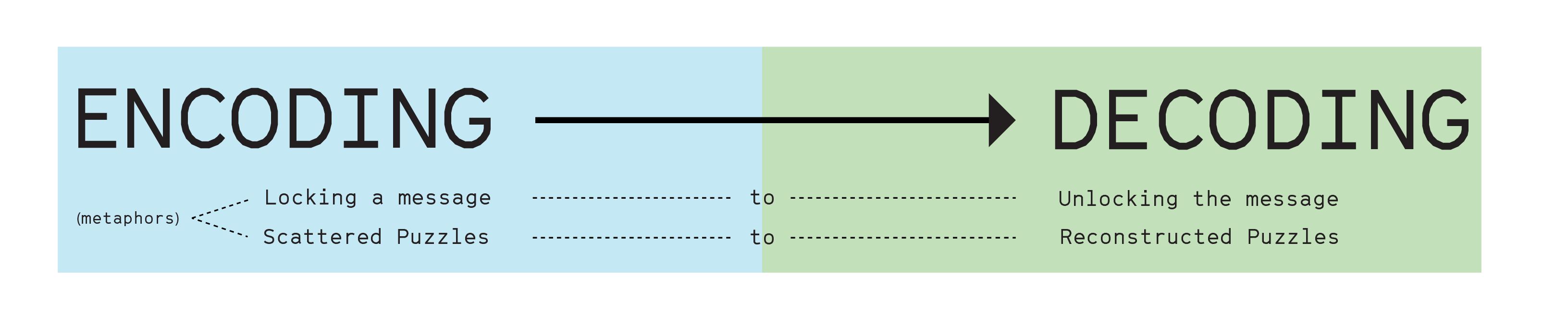
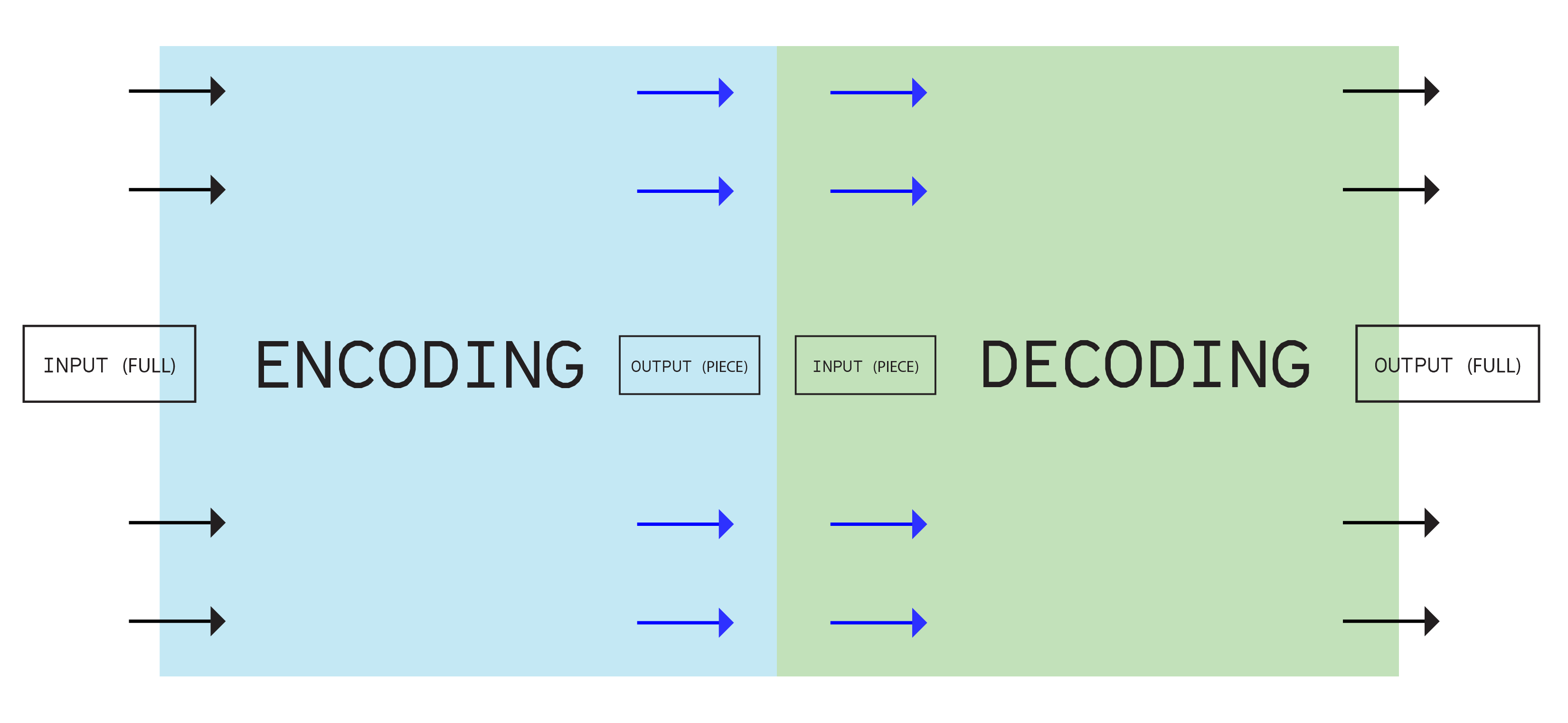
Diagram of Encoding and Decoding
Encoding & Decoding
I spent time reflecting on the processes behind my experiments and noticed recurring patterns throughout. These processes often involve converting, deciphering, and reconstructing, which are techniques that are similar to the methods of encoding and decoding used in image processing.
Encoding involves the process of putting a sequence of characters (letters, numbers, punctuation, and certain symbols) into a specialized format for efficient transmission or storage. In my experiments experiments, these processes extend to techniques like color segmentation and matching numerical values.
Decoding, on the other hand, involves the conversion of an encoded format back into the original sequence of characters. The process of decoding here means converting into different usable forms such as, an analyzed text, image generation, and poems. I created a diagram to understand better what encoding and decoding positioned in my experiments.

Quantifying Memories
Although the experiments I have done used different tools and techniques, they all have the same objective which is to find different ways to quantify memories — expressing human experiences as quantified figures to show the differences between human and machine memory. When compiling these experiments, I thought it was interesting on the way I divided each experiments into layers of processes. Thus, the idea of a journal came up to my mind.
A Journey To Quantify Memories — the idea behind it is to create almost like a report book where I tried to retrace a specific memory by learning machine memory. One thing that I realized when trying to differentiate human and machine memory is that I am not just learning about machine memory but I am also learning about human memory. I believe that this process involves an act of retracing the memory as well. If you keep replaying a video, you will get direct access to the memory without needing to be reminded.
However, what if you only get the gist of it, like fragments from dissecting the images and texts? Would leaving spaces for imagination helps us remember our experience better?


Book of Life
To explain the relationship between fragments and imagination better, I have a good example — a book that is full of experience when you read it occasionally. There was this book that my father has that comes from fortune telling that shows his age line, almost like a book of life. It shows his life journey, past and future, with each year labelled with his age. Each year tells a story, an event, or at the same time a reading (message). However, these messages are written in poems, using abstract words that are mostly metaphors.
One thing that I always keep in mind when reading the book is that to not take it seriously — meaning not to fully depend on the readings. Hence, I don’t read this book too often. Sometimes once in two years, or even five years. When reading the past and future, the experience seemed different.
These experiences may be caused to the way I interpret the poetry, and the time I read it. It was fun and exciting to foresee the future ahead, and to recall the past while reading these fragmented interpretations. The experience of reading it each time feels new yet fluid, as each time I read it, I have different interpretations and imaginations. I believe that this is the beauty of our memory. The way we recall involves reimagining the past and future experiences. I hope to communicate this idea of how our experience is different from machines.


The Library of Babel by Jonathan Basile
The Library of Babel
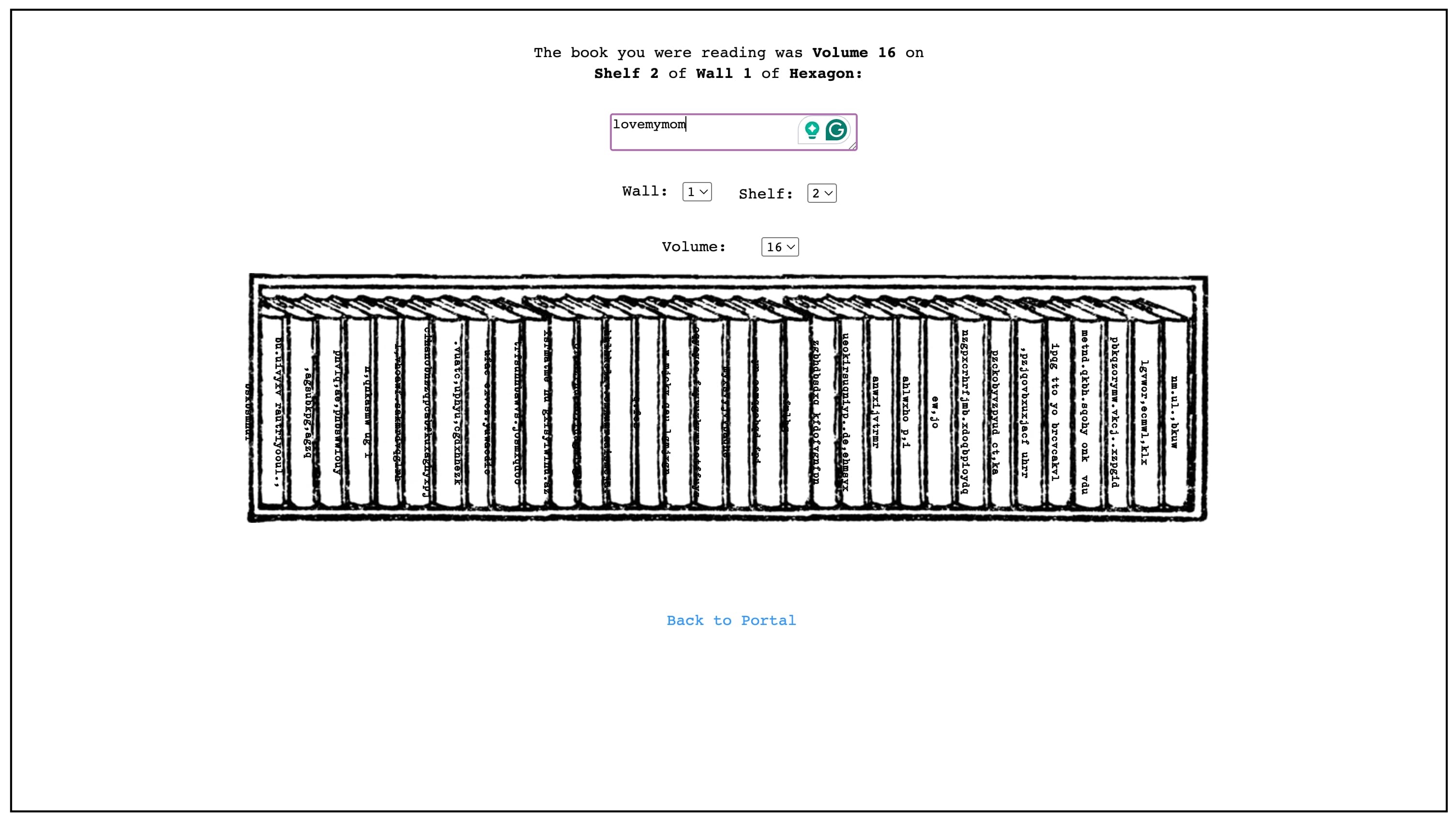
I shared this experience with others, and my partner referenced a particular source, noting that the concept of "discovery" from that reference reminded him of my experience when I opened the book. The Library of Babel is a short story by Argentine author and librarian Jorge Luis Borges. It conceives of a universe in the form of a vast library containing all possible 410-page books of a certain format and character set.
Jonathan Basile created a website that functions as a database inspired by the literature. The website contains every possible combination of 1,312,000 characters, including lowercase letters, spaces, commas, and periods. If fully completed, it would encompass every book that has ever been written—and every book that ever could be. This includes every play, song, scientific paper, legal decision, constitution, piece of scripture, and more. Currently, the website contains all possible pages of 3,200 characters, totaling approximately 104,677 books.
Although the literature is fictional, the creator was able to imagine and construct an interpretation of what such a library could be in the digital space. By using syntax, the creator designed a system where all possible combinations are generated and accessible. I found the concept of "discovery" particularly interesting here. Someone mentioned that if one had the time to browse through all these combinations in their lifetime (which is realistically impossible), they might even uncover the world’s deepest secrets.
Connecting this back to my experience of opening the book, I resonate with the sense of endless time that the book says. I don’t remember the exact words I read in the past, but the feelings I had still linger. Each time I revisit those pages, I find myself interpreting them differently, discovering new meanings shaped by my present state of mind. The experience feels like an ongoing dialogue between the past, present, and future, where what I uncover is constantly evolving.