
WEEK 3
TRYING COMFYUI

Revisiting Idea
After having a discussion with Andreas and a week of contemplating, I realized that there are no personal values that involved in this publication idea. If I want to create a publication as the final outcome, there should be a lot of reasoning behind it. It is a safe option, however, I do think that it wouldn’t enhance my project with just the publication being the main outcome. However, I could revisit this idea for presenting my semester 1 works in the future for the table setup.
Also as part of the nature of the atelier, I should integrate computational strategy as well. Hence, the idea of publication is not going to work if I were going to just use its format without any special reasoning behind it. There should be a purpose, value, and impact behind the project. I felt like I have been indecisive and impatient over my project. I should just start making something.
Important Notes to myself: theres no need for a conclusion for it to be a project
Dream Maker by Hong Cyan
DreamMaker
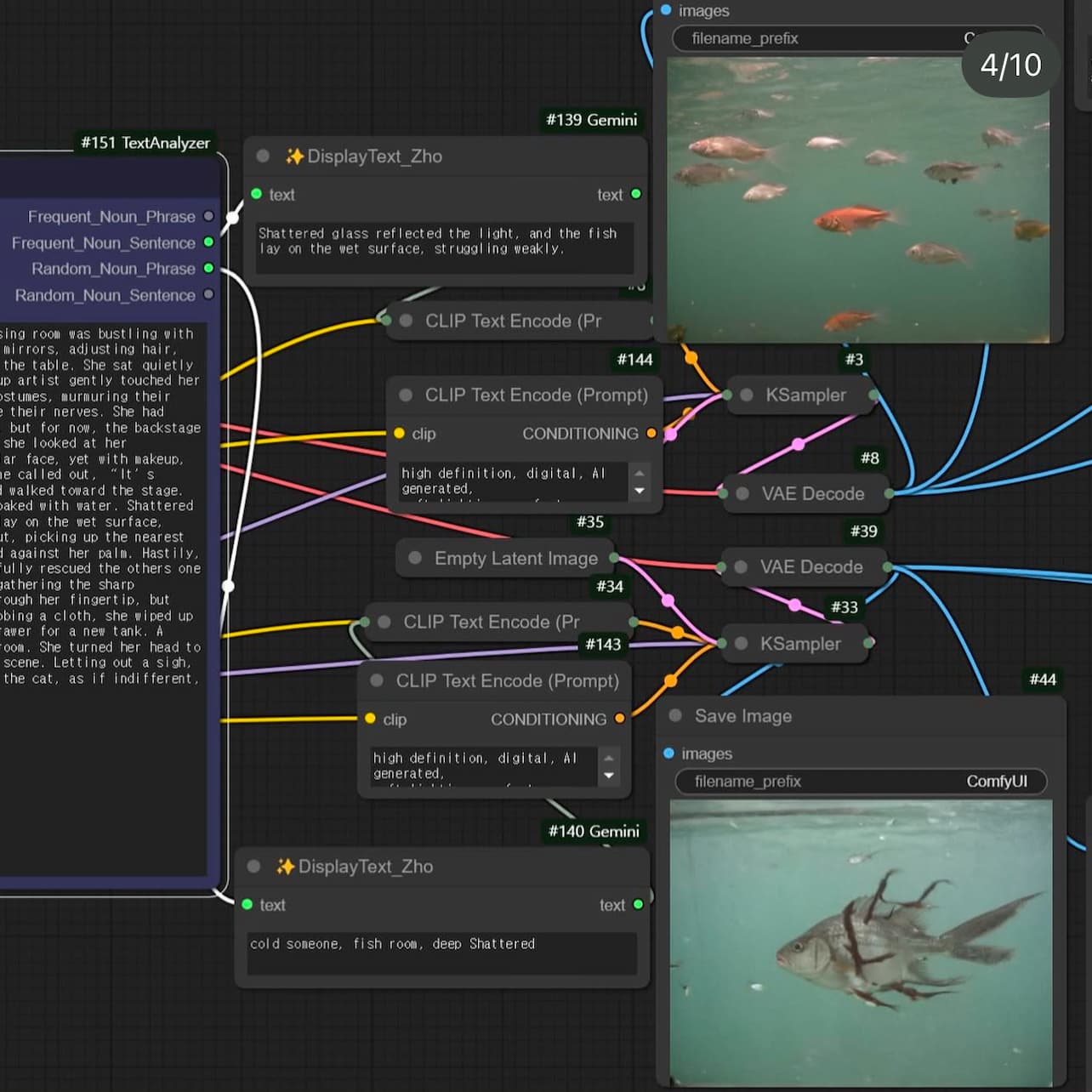
As I struggle with my direction, I came upon this project, DreamMaker — a device tool that creates dream from written text inputs.
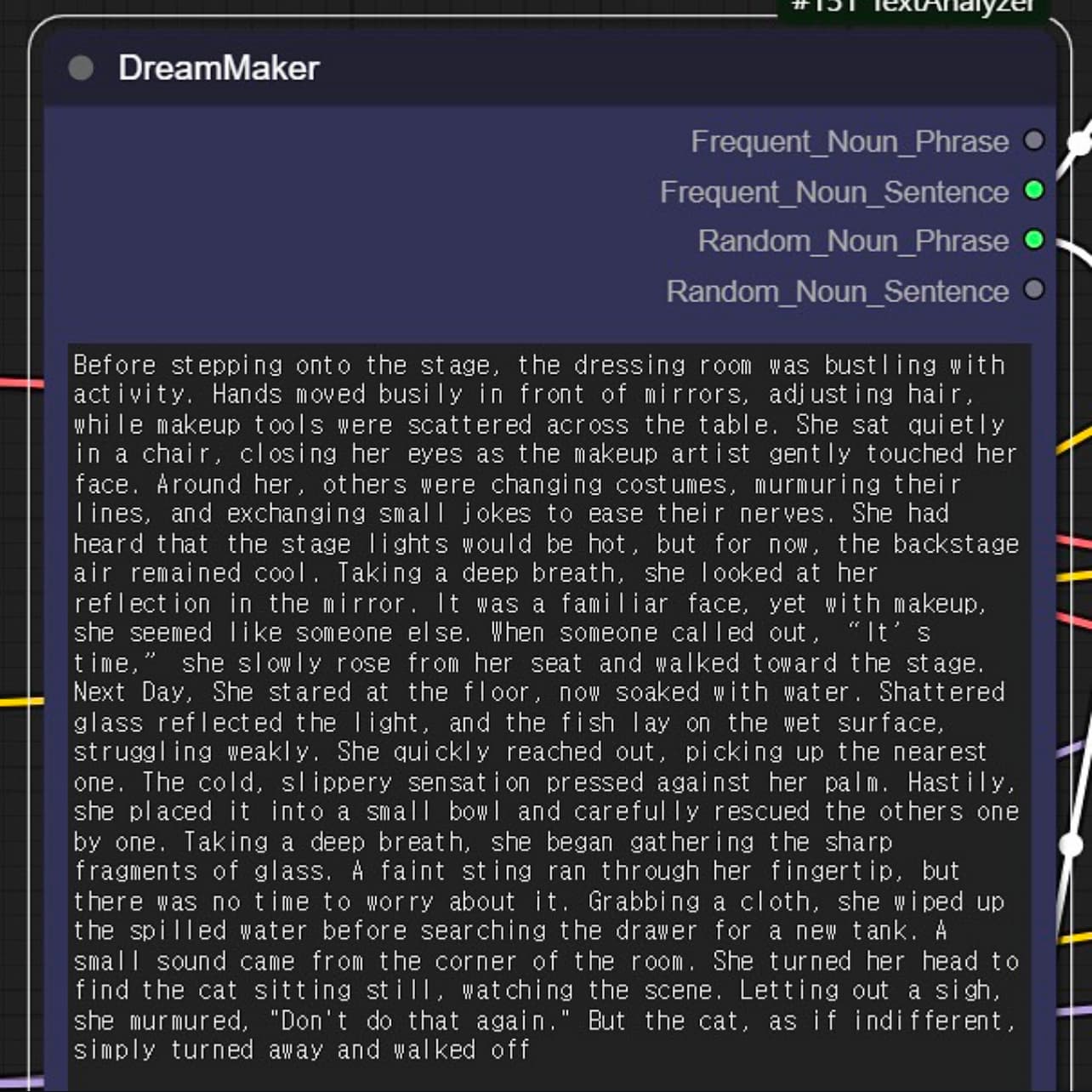
The artist uses ComfyUI to work with stable diffusion models closely. Working with prompts, she created her own workflows consisting of custom nodes and combined it with several python libraries to generate images and videos with multiple AI models. This process of writing and re-imagining scenarios through prompts is very similar to the way a person dreams, she mentioned.
She names it Dream Maker as it collectively converts selected words and sentences from a written scenario to a sequential videos, almost like a “Filmmaking Automation System”. User can just enter a scenario through this “device”, and the computer will randomly select the inputted words to create layers of visual outcomes.
The outcomes shown from this exploration were vivid-like. The final video is abstract, it doesn’t make any sense when you look at the sequence. However, I found this interesting as it shows the various possibilities you can generate with the AI models. The flaws from the outcomes show visual qualities that I found aesthetically pleasing. The irrational scenarios coming from the identified objects are almost like a forgotten memory.
It is interesting to see how you can customize the generative structure on your own, which is different when you generate an image or video through platforms, such as Runway and Midjourney. Hence, I wanted to give this program a chance to explore the potential of Generative AI. It would be quite interesting as well to use it conceptually as a way to re-imagine our memory through prompting.






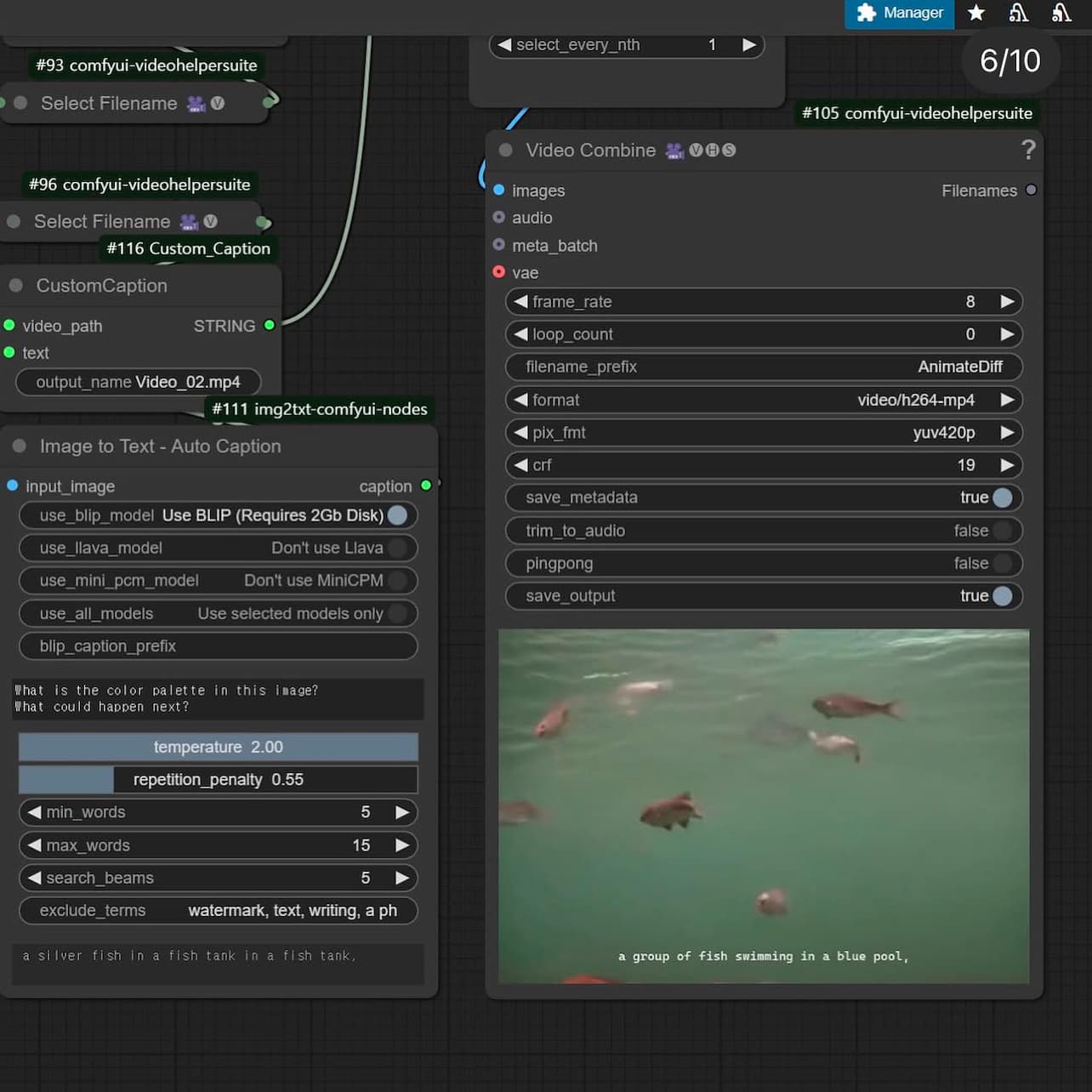
Working with ComfyUI
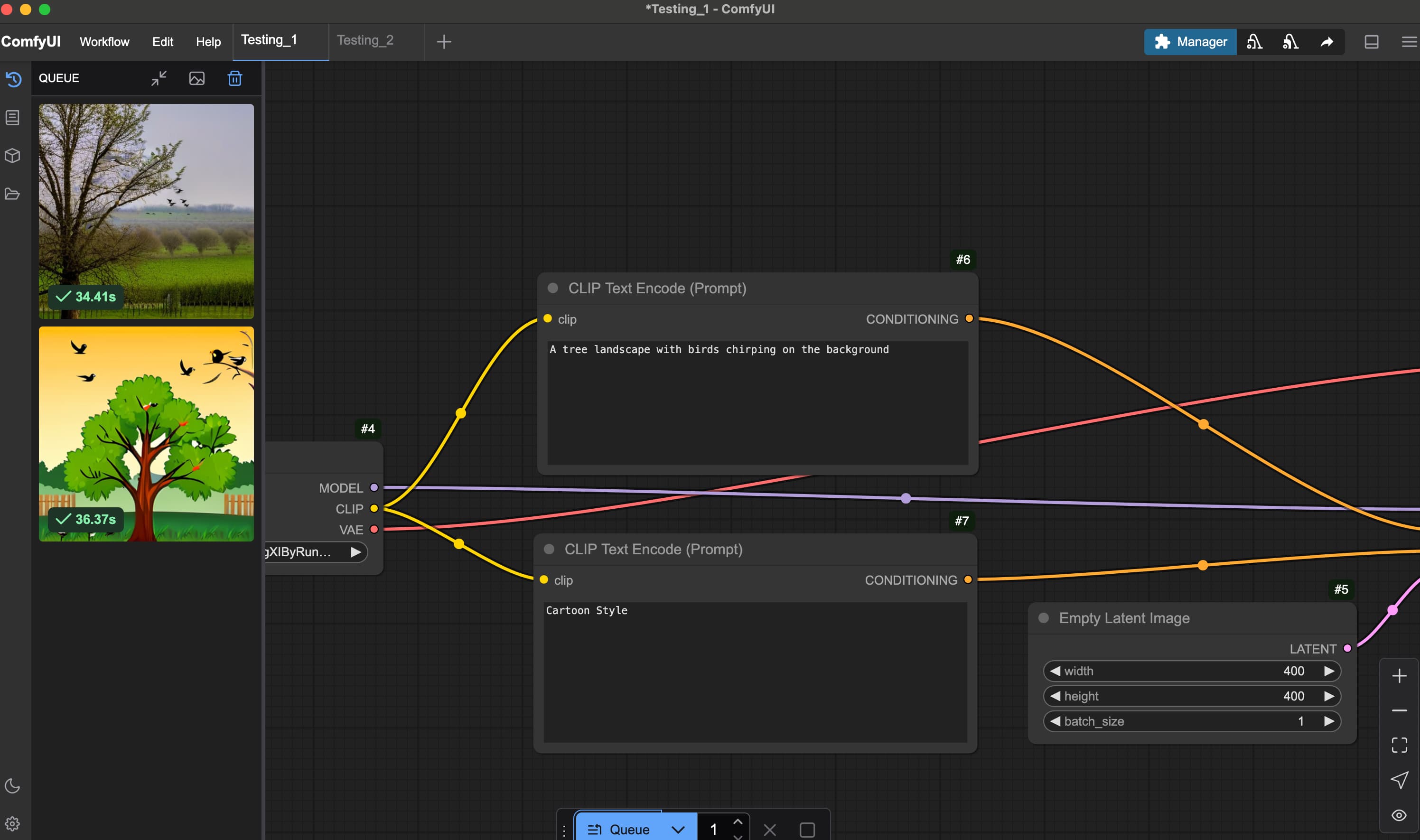
I decided to generate an image with the most basic workflow (text-to-image generation), and I tried playing with controlling the parameters on the sampling process.
One significant advantage of ComfyUI is its text encoder tool, specifically the CLIP (Contrastive Language-Image Pre-training) Text Encode. This tool converts textual input into numerical embeddings that Stable Diffusion can interpret to generate images. The CLIP text encoder plays an important role in defining what elements I want to include or exclude from the prompt.
A particularly useful feature is the ability to apply positive and negative conditioning. This allows me to emphasize desired qualities while excluding unwanted elements, such as text overlays or watermarks. For example, as demonstrated in my test results, without inputting the term "cartoon-style" in the negative CLIP resulted in an image featuring a graphic tree and birds rendered in a playful, illustrative style. By refining these prompt conditions, I can better control the visual qualities of the generated outcomes.
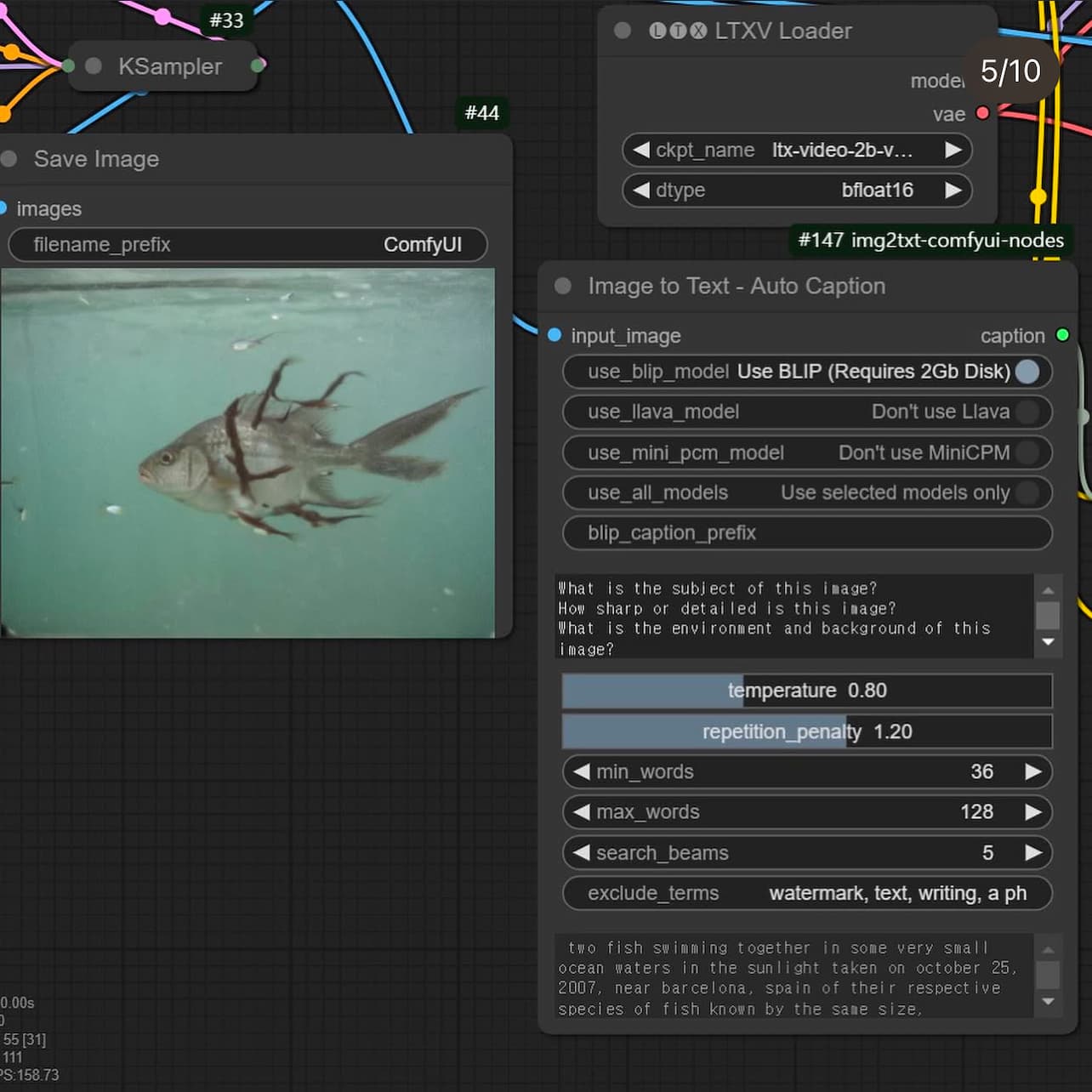
Basic Parameters
There is also a node called KSampler that controls the image generation process by manipulating noise levels and applying conditioning to create new data samples. While experimenting with this node, I explored a specific parameter called CFG (Configuration Scale), which influences how closely the generated image aligns with the initial prompt.
When set to higher values, the results adhere more strictly to the prompt; however, this often comes at the cost of visual quality, resulting in distorted objects and altered colors. As seen from my results, pushing the CFG parameter too high can make the colors and shapes appear inconsistent or "wonky."
Through repeated experimentation with this workflow, I realized that I could automate the generation process to produce multiple visual outcomes from a single prompt. This observation reminded me of how AI memory behaves differently from traditional computer memory. Unlike static computer memory, AI memory is dynamic — often repetitive, yet never entirely the same. This “generativeness” allows AI to create outputs that are both familiar and unpredictable.
Inspired by this, I am interested in creating my own workflow that builds layers of outcomes from a single written prompt. This approach would allow me to further explore the evolving and dynamic nature of AI-generated content, blurring the lines between the artificial and reality in generative AI.