WEEK 4
DESIGNING WORKFLOWS
Layers of Memories
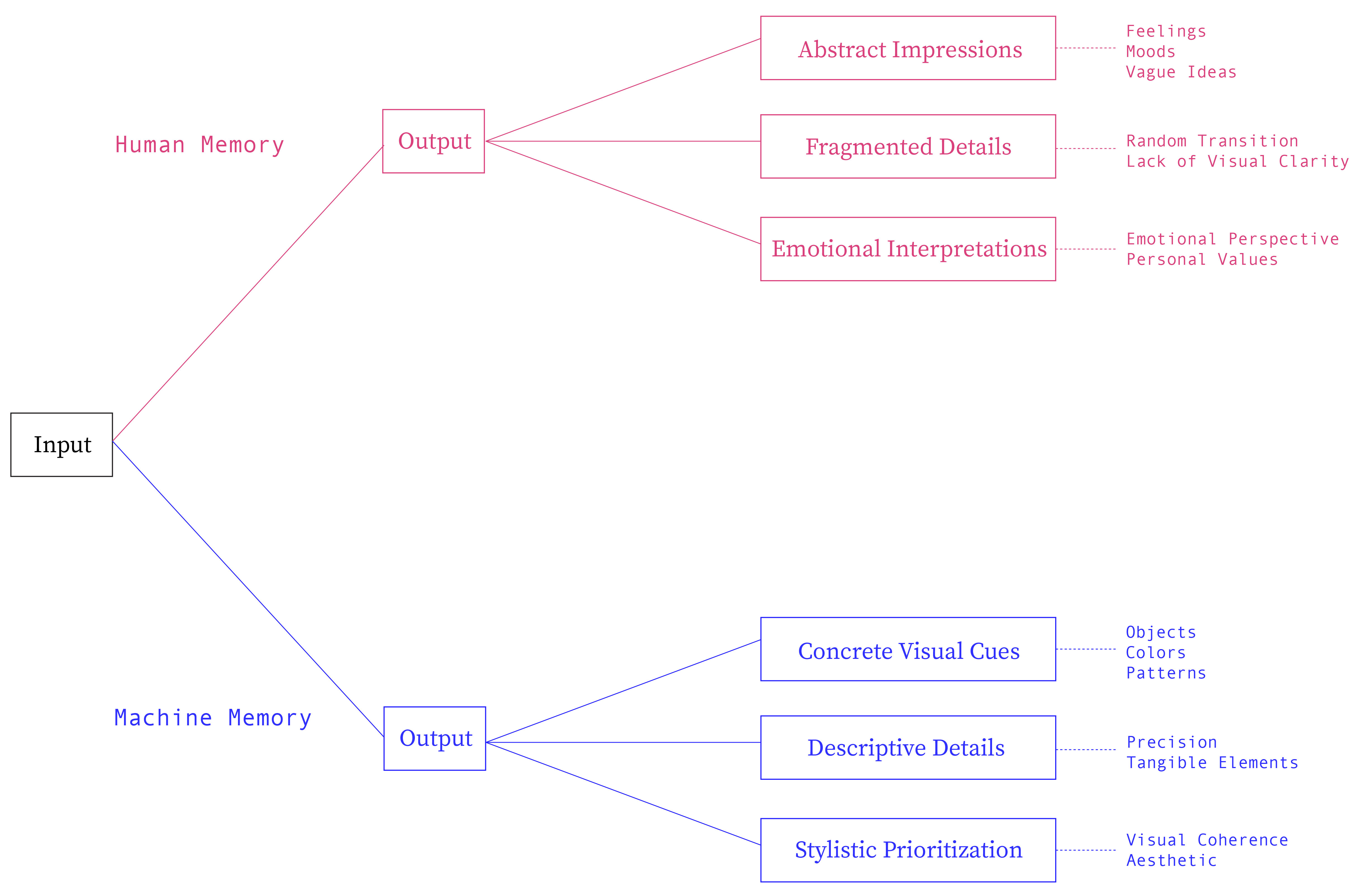
The idea that underlines these experiments was to create layers of memories through a text prompt. AI often focuses on concrete subjects, has key descriptive details, and prioritizes styles first. It simplifies complex or abstract ideas into the most visually or textually relevant component (visual cues are important). Meanwhile, human descriptions are inevitably abstract.
When we recall our memories, we often write down subjective details in fragmented ways. Human writings are less descriptive, and oftentimes the imagined scenarios are more fluid. When seen as a text-to-image process, it becomes more unilinear compared to AI generation.
The questions that
push this experiment:
1. Can we integrate our fragmented way of recalling through machines?
2. Can we integrate the fluidness of the human mind into the process of text-to-image
and image-to-text generation?
3. Is it possible to retrace our memories through machines?

AI Images generated from the same prompt
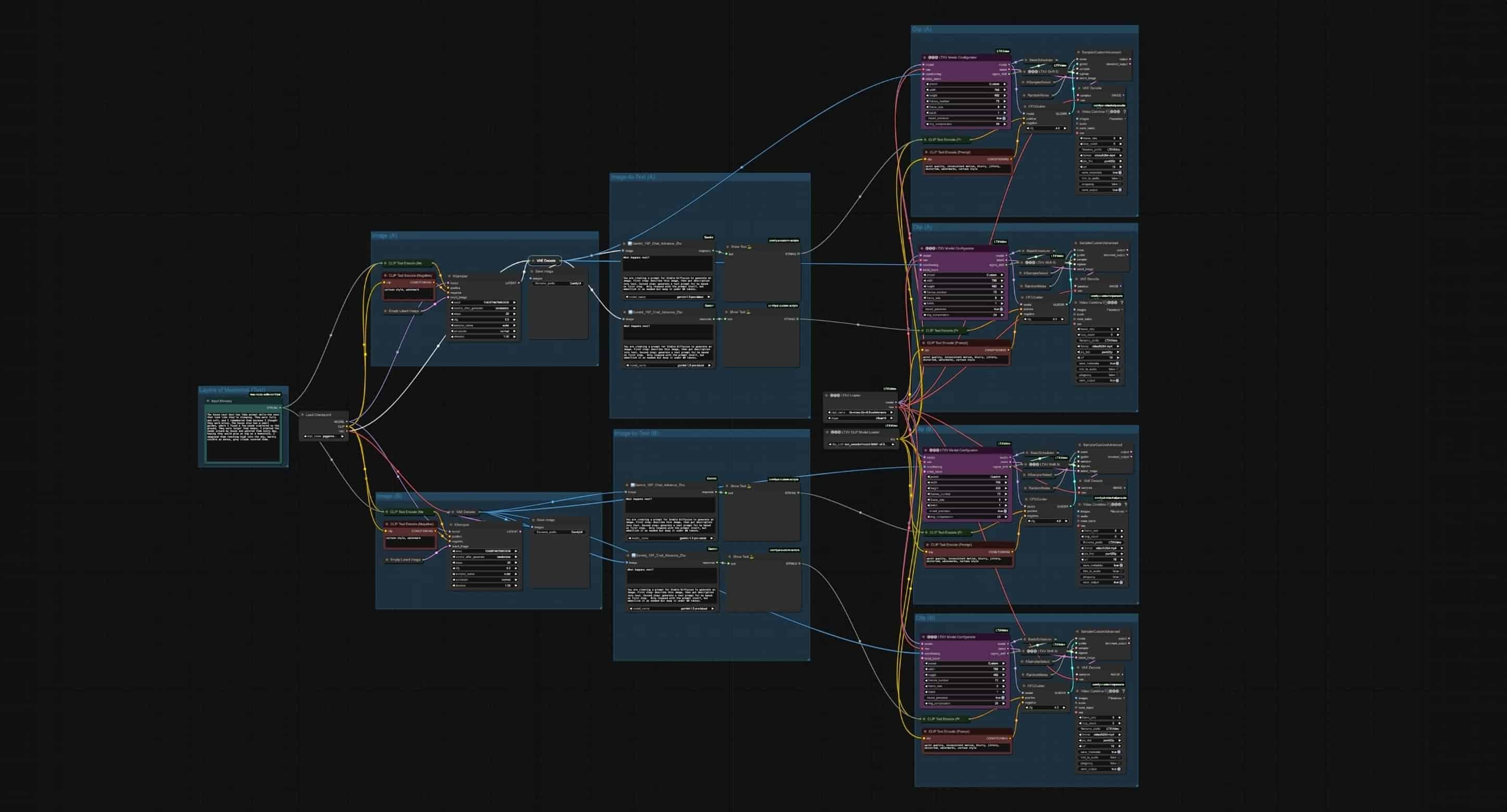
Building The Workflow
ComfyUI made it possible to adjust the parameters of the generation through prompt weighting. The outcomes show visual qualities that I found interesting, the imaginative writings led to generating outcomes that are vivid-like, almost like a forgotten memory. In this experiment, I focused on creating a workflow using two model checkpoints — a saved version of a model during training — for image and video generation.
AI-generation images can be repetitive sometimes, however, their outcomes are never the same. They differ in values and concrete measurements. There are things that seemed more dominant but things that are not visible to the model, so some of the scenes written in the text prompt are not even in the generated images. Benefitting from this, it can create layers of outcomes that are similar yet they are also different.
“Looking behind the bus window, I could see the pale blue sky. As it drove on the highway, I could see the vast field of crops of plants. Groups of birds are flying in the sky, and the wind blows the trees and flags. I could see the mountains far away, barely visible due to the dense clouds. I could see the teared-down posters remaining on the tall billboard. The tall billboard looks old, as moss and plants are covering them. The window scenery will always remain in my memory.”


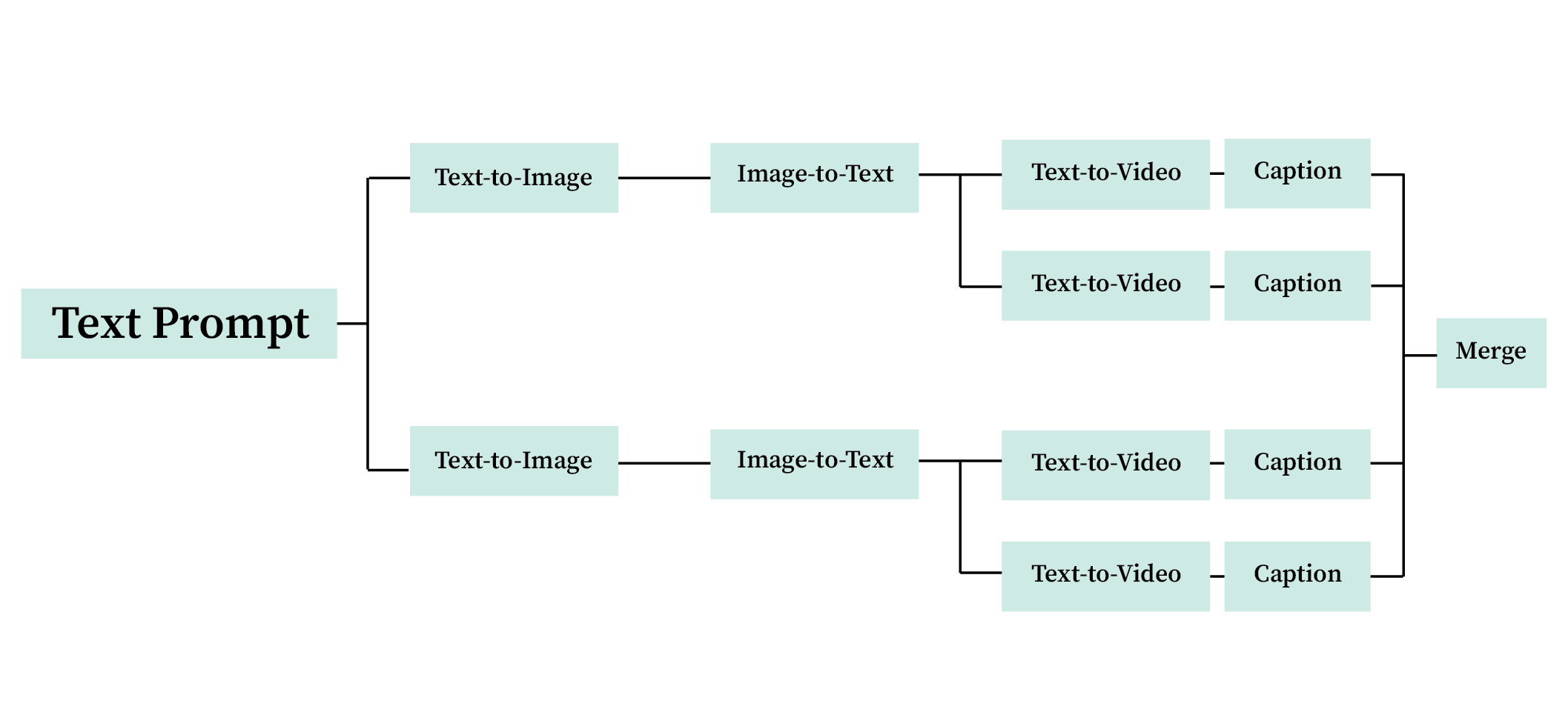
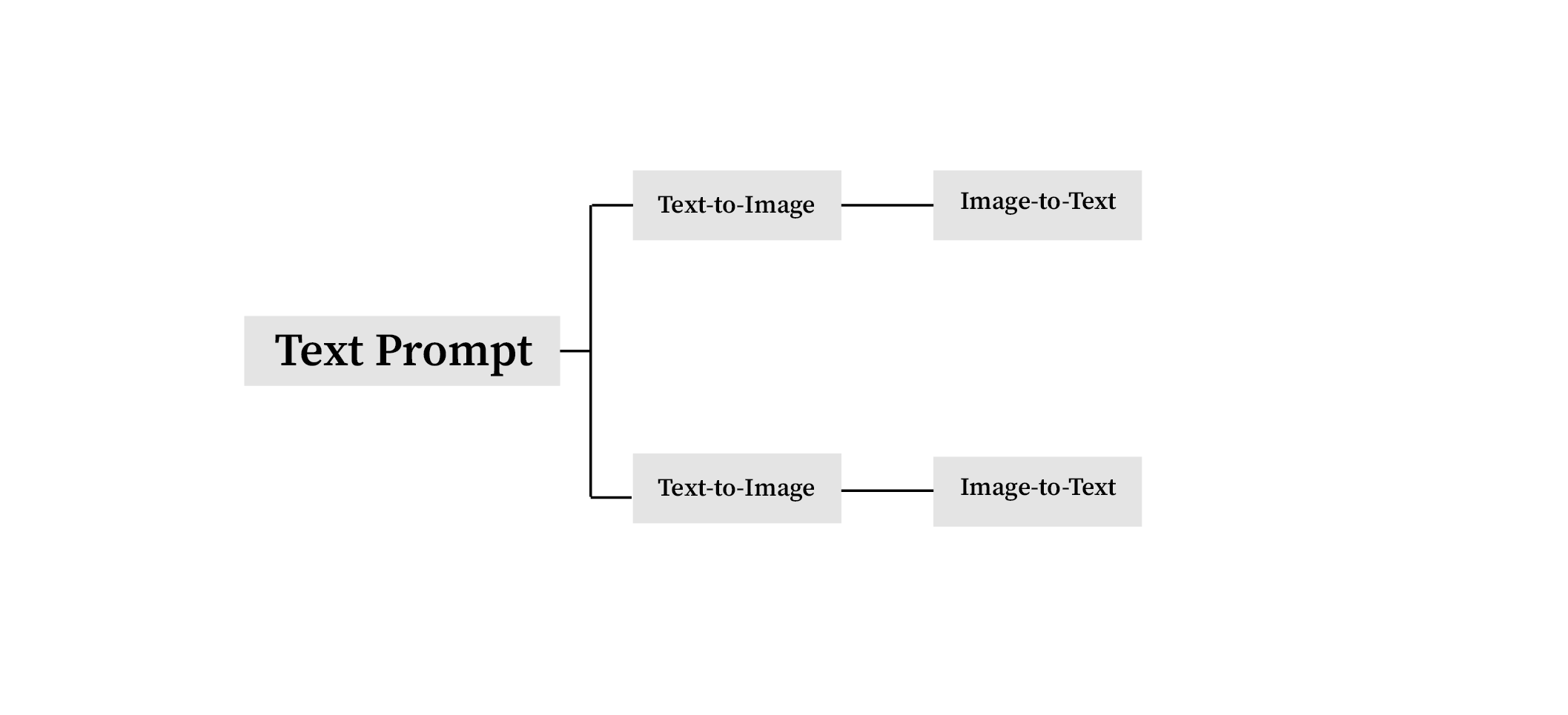
Text-to-Image-to-Text
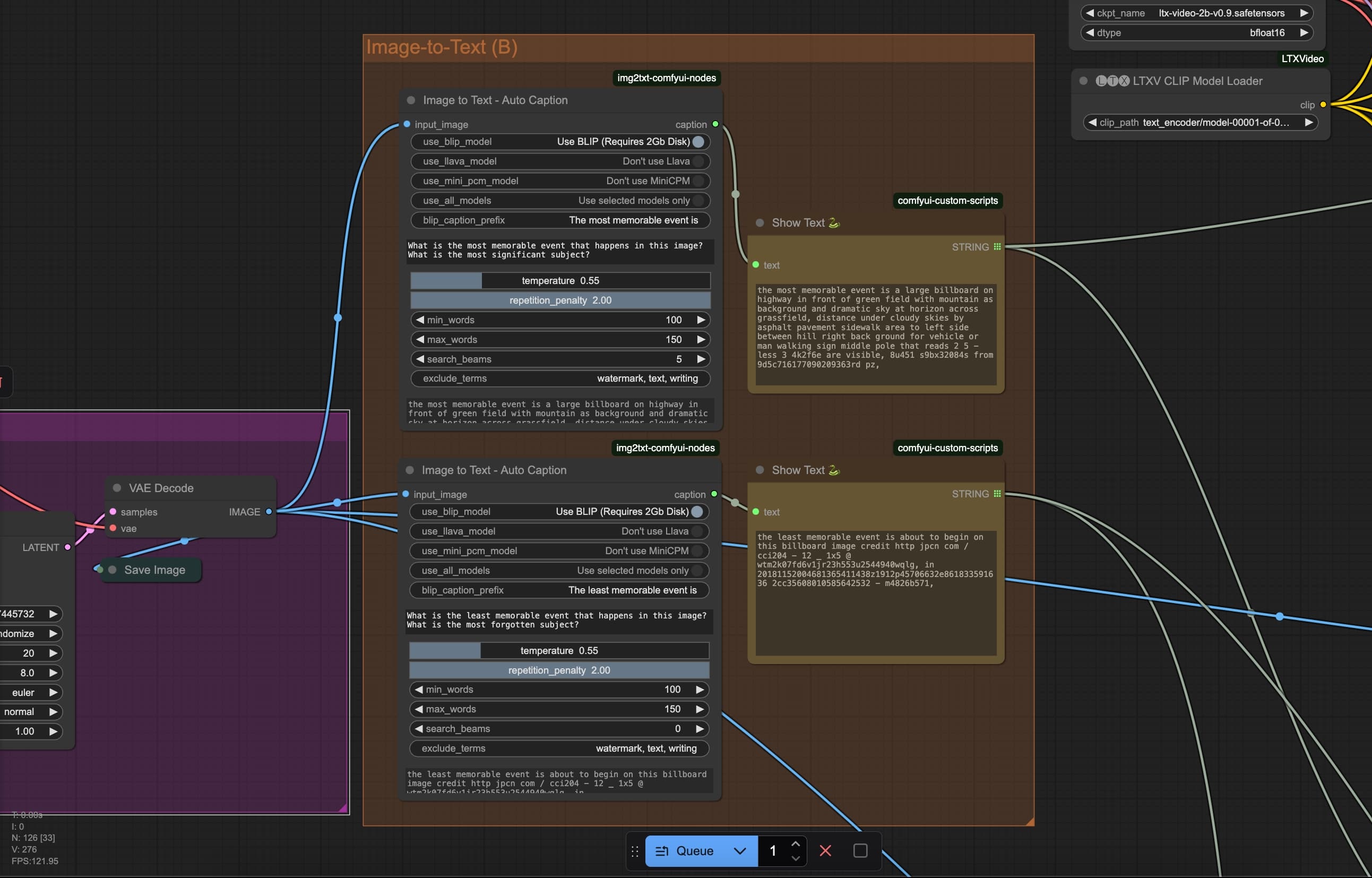
The process behind the workflow is to generate layers of outcomes through two different paths. After experimenting with basic workflow (text-to-image), I tried to integrate some custom nodes that can generate descriptive captions for images. By seeing this tool as a system that “see” and “describe” the images passed down to, I asked specific questions for each node, and the extension generates answers based on the image content.
The particular node uses machine learning models to generate the captions. I can use the BLIP models to automatically generate text from image, or both BLIP and LLAVA to automate image to image process. By generating captions, I can create a more detailed prompt that can be fed back to the model checkpoint to generate new images.
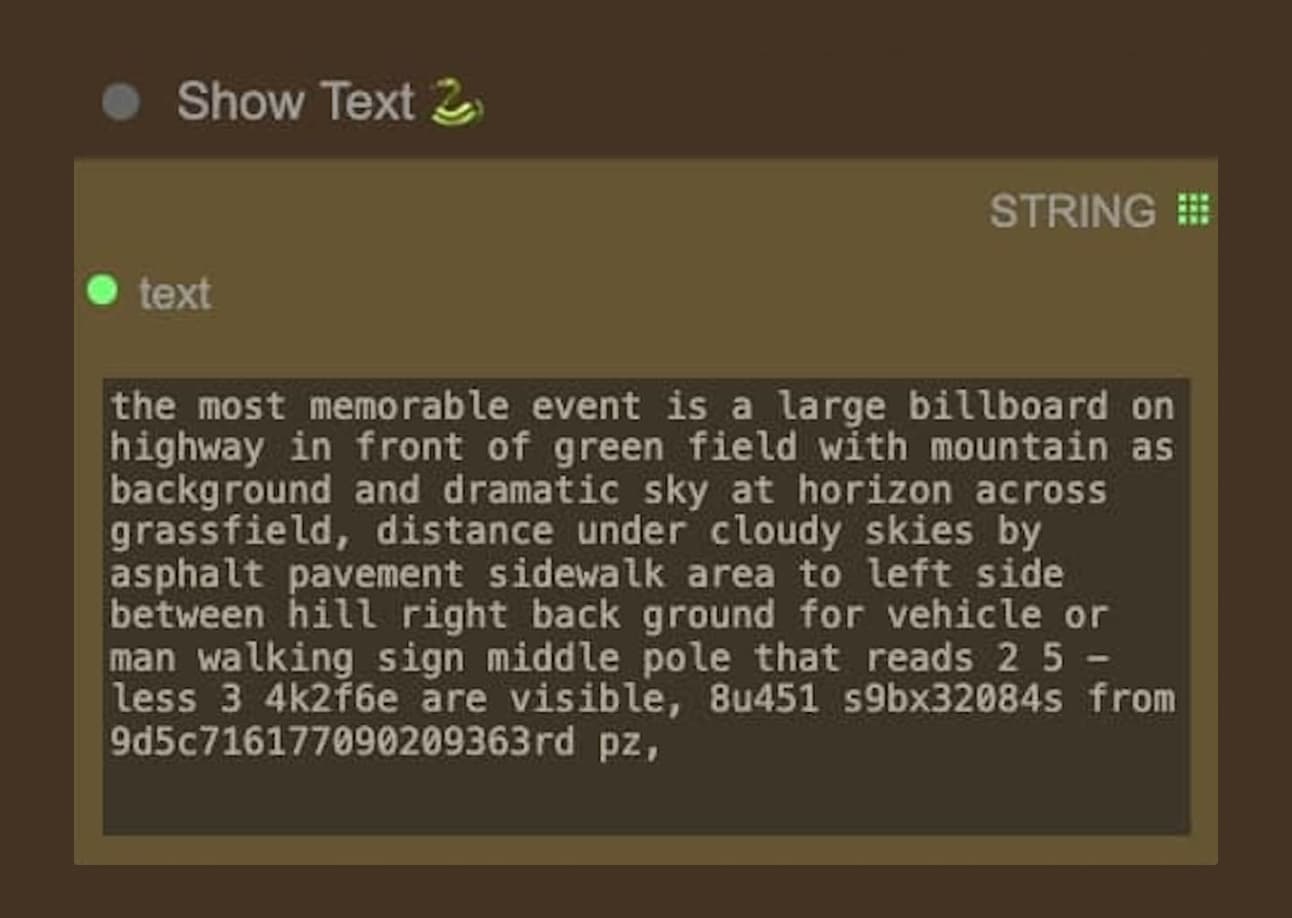
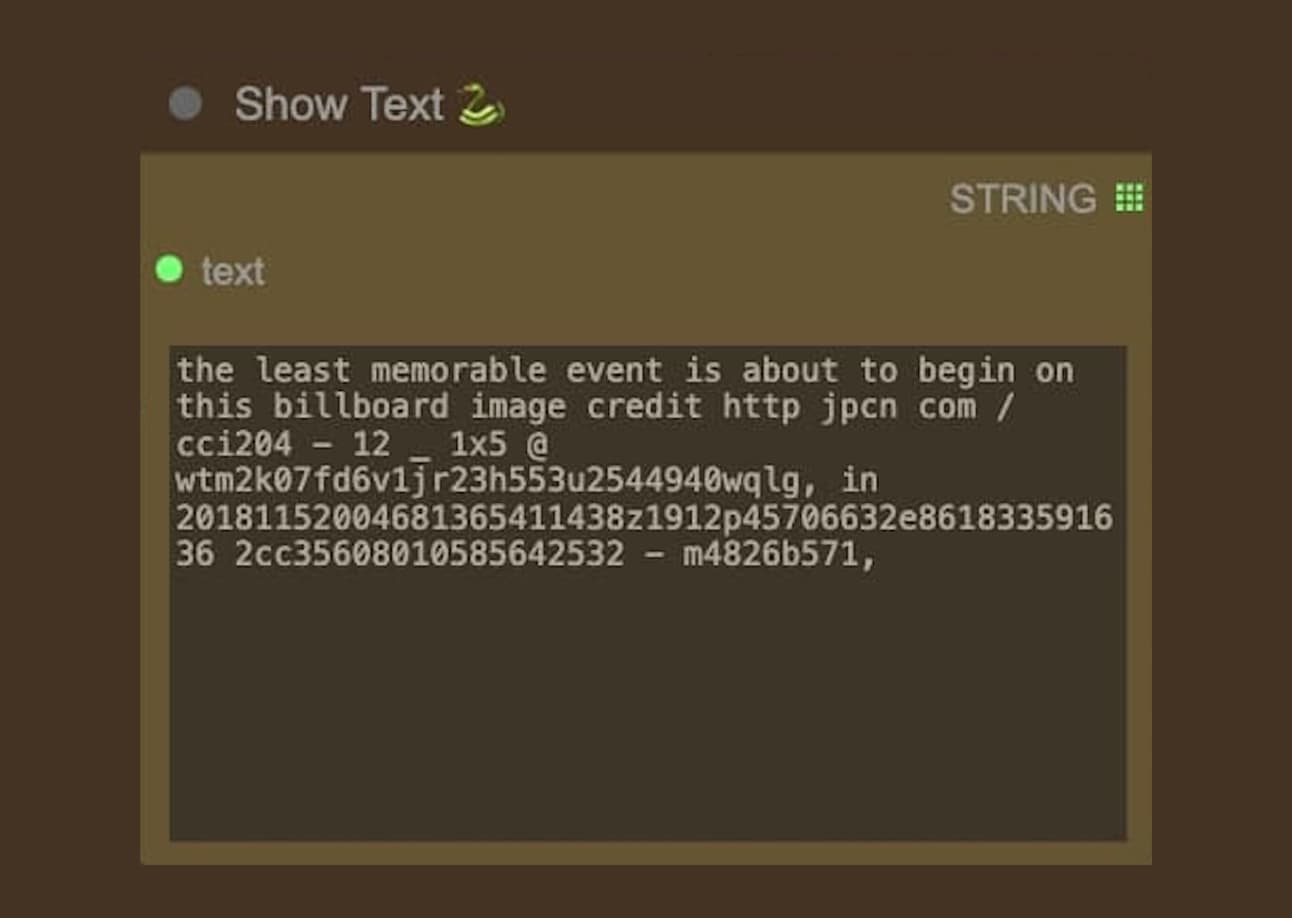
In this experiment, I tried to create different layers of outcomes by creating different prompts using this extension. For the first layer, I asked the question “What is the most memorable event that happens in this image?” and “What is the most significant subject?”; whereas the second layer I asked the opposite “What is the least memorable event that happens in this image?” and “What is the most forgotten subject?”. By exploring this feature, I could create a more diverse input of outcomes with a single prompt as the initial point.
Temperature and Repetition Penalty
Seeing the answers given by the models from these questions was quite interesting. While it doesn’t really give a meaningful answers as much as how meaningful the questions are, you can see how it could sometimes add a different scenarios to the image content it has “seen”. It’s like adding another layer that fits to the original story, which is what a prompt generation is used for.
As these images are passed down to the model, the model answered the specific question based on the image content. The answers sometimes add another layer to the story — the scenario that the model has “seen” from the image. Like how it adds “a pavement sidewalk for vehicles or a man walking”. Although it is quite subtle, it could bring effects, it creates another layer, somehow like a perspective that is missing from the initial prompt.
These answers also depends on the parameters that have been set as well, particularly the temperature and repetition penalty in the node. The temperature controls how random the text generation could be. Higher value may reduce the randomness and focus on precision, while lower value generates a more diverse and creative generation, but it could also become less cohesive. The repetition penalty, on the other hand, is used to avoid using the same words when sets on higher values.
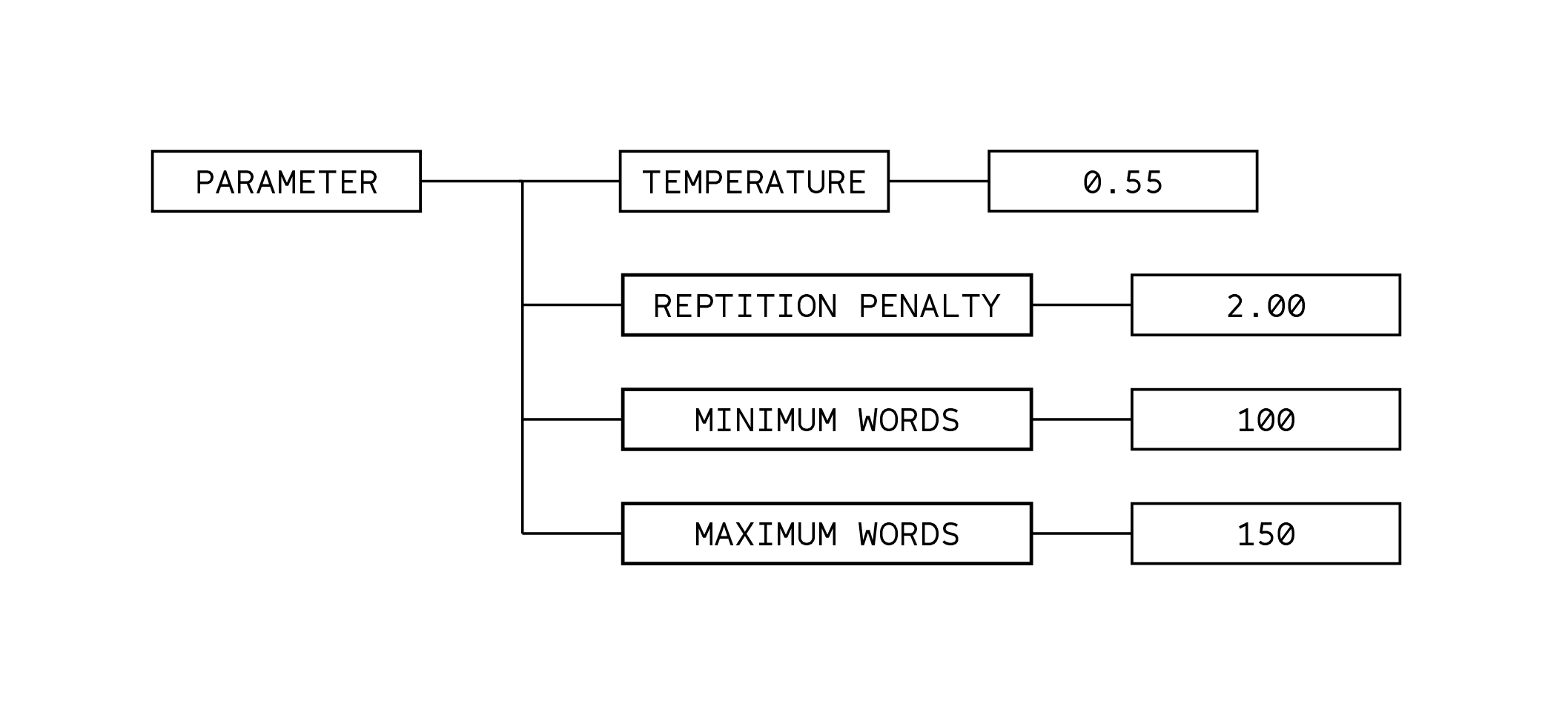
For this experiment, I used a lower temperature for more precision and avoids randomness, and I put the repetition penalty in higher values as it will be used as an additional prompt for the next generation process. The results, however, could sometimes not be consistent. As you can see, you could get random words and gibberish numbers. I believe that this could be the flaws of using a cheap and fast text generation model, as it sometimes gives our better quality despite the parameters being set the same.
“A bird that has broken wings is lying on the ground with patches of grass. The wings are broken and the bird’s feathers are torn off, some of the feathers are scattered over the grass. The wings are twitching due to its pain. The patches of grass seem dying as well, they slowly turn brown.”
“The leaves are filled with holes, as a very small green caterpillar is eating the leaves. The leave subtly moves up and down as the wind blows. Some leaves are green, some are yellow, and some are brown, dying. Bleak and grey, the nature is still beautiful.”
“Bleak and grey forest, foxes are roaming around the ground, the fog is subtle, and the dark trees are tall, foxes are emerging from behind the trees, some just sit there.”
“At the top of the hill, the sight is vast. The blue pale sky is filled with grey clouds. The trees beneath are visible, There are moments of silence, yet it seems unreal how the sight of the mountains is slightly flat.”
“It was wintertime when the snow was falling. The ground is covered with snow, but some are not, showing the bare ground. The snow falls heavily as the thick dense clouds move faster in the pale blue sky. What a life, the sight of a white wolf running from the distance, it seems happy but tired.”
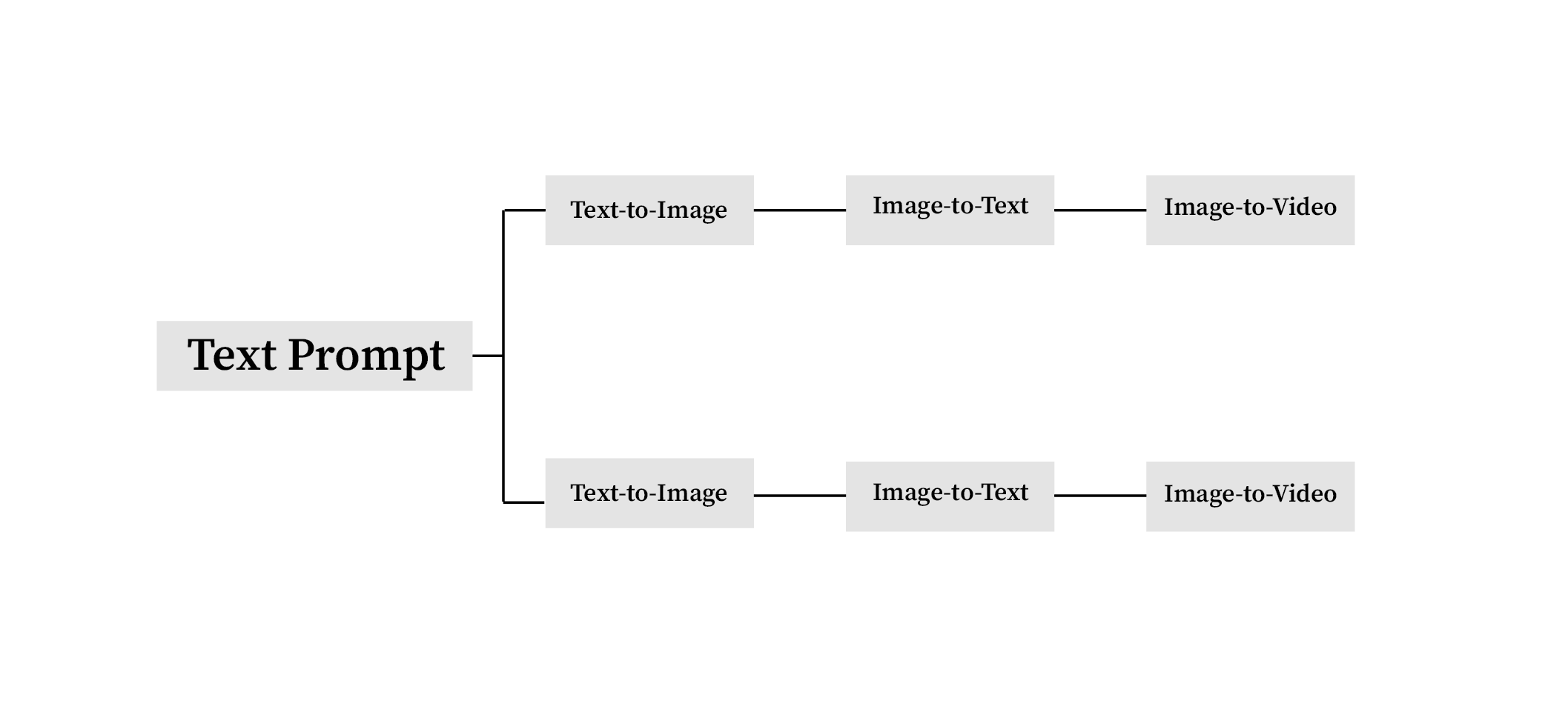
Text-to-Image-to-Video
These multiple prompts generated by the extensions are then used as guidance to produce videos from the previous images. There are multiple ways to generate videos using the model. You could generate a video from an existing image, this would mean animating the image you input (Image-to-Video), or you could even generate videos from written texts (Text-to-Video).
In this experiment, I tried to generate videos using the existing images that have been generated from the first layer image generation process. With the texts generated from captioning the images, I used them as guidance to generate videos. As seen from the results, I realized that the visual outputs generated has not so good qualities when compared to the videos generated from text directly.
Although I quite like the movements it created and also the flaws, it doesn’t really have that much of dynamics as it generates the movements based on the images that has been given, while the text just acts as an additional guidance. This means that if the guidance doesn’t have precisions, it couldn’t really read and generate good qualities. For example, sometimes the videos generated are not even moving.
Text-to-Video
I tried to do another tests of how the videos generated from text could result better qualities. In this part of experiment, I created five different prompts, some are more accurate, while some are less detailed. These prompts are then used in a more basic workflow than the one I have been building (Text-to-Video). As you can see it could create a more dynamic movements despite the prompt being vague nor accurate.
Some flaws are apparent, however, some are less apparent. Such like the foxes roaming in the forest. From afar, you couldn’t see what is wrong with the videos, you couldn’t tell whether its real or fake. However, as you see the videos, you could see that the animals are moving in a weird way, like its not meant to walk in that way. This is the quality I tried to aim for, between whats real and whats artificial.
As you can see from the birds movement here as well. It appears fine at first. However, if you look closely, the birds are moving in a weird way. It seems like they are flying still, almost like a kite. This subtle mistakes in these visual outputs are what I found particularly interesting from the generation.
“Looking behind the bus window, I could see the pale blue sky. As it drove on the highway, I could see the vast field of crops of plants. Groups of birds are flying in the sky, and the wind blows the trees and flags. I could see the mountains far away, barely visible due to the dense clouds. I could see the teared-down posters remaining on the tall billboard. The tall billboard looks old, as moss and plants are covering them. The window scenery will always remain in my memory.”




Final Results
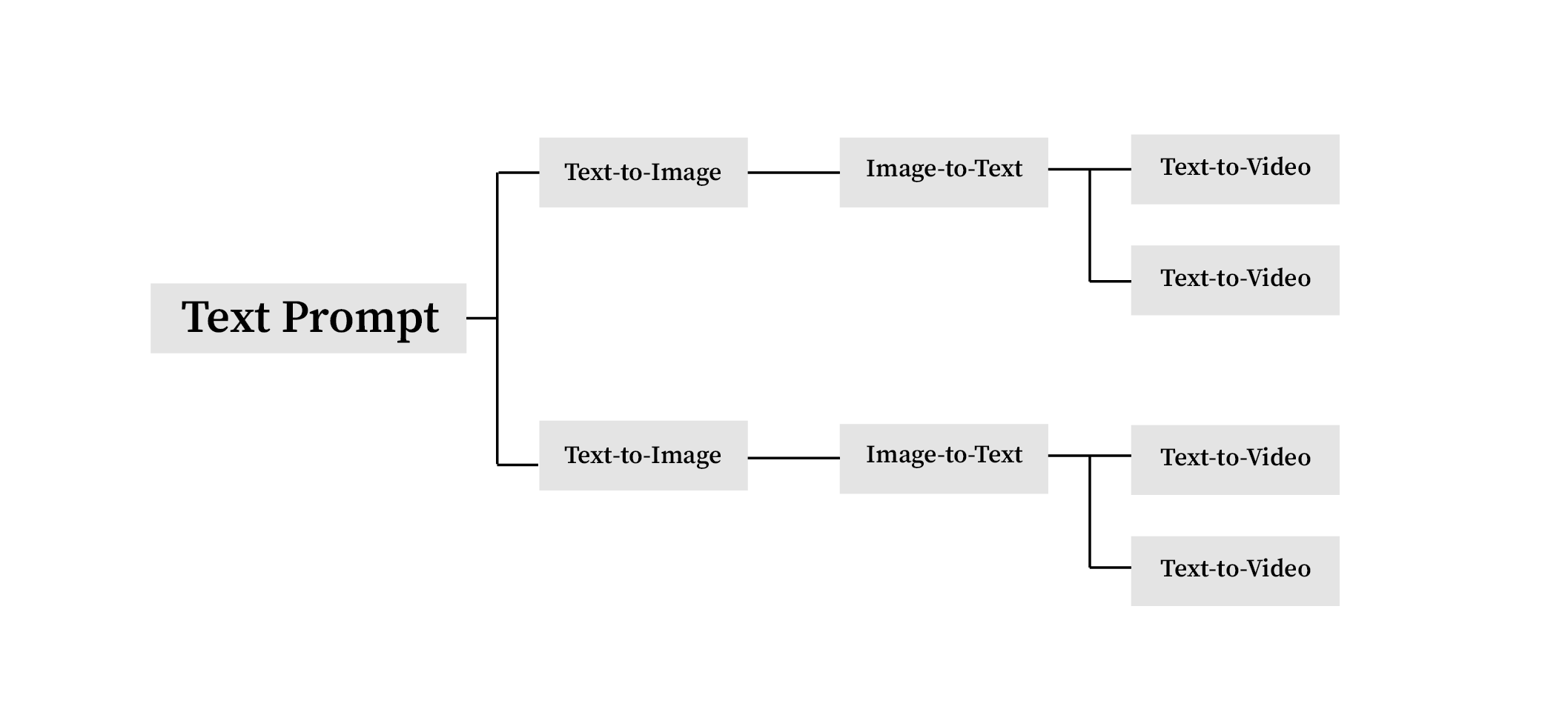
Text-to-Image-to-Text-to-Video
Therefore, I decided to tweak my workflow again. This time, instead of generating the videos from the images, I decided to input the generated text from the images and passed it as strings for prompts to generate videos. It seems like a better way to achieve the quality I am aiming for.
As seen from the results, the generated outputs become more diverse. Sometimes, it is even outside of the box, like why would an American flag comes to the picture. I wouldn’t say it is really a problem, but I would like a more cohesive scenarios. This is something that I need to tweak on the parameters of the Image-to-Text extensions.
Although its more diverse, I quite like how it adds another layer such as a train and a railroad, or a sign directing the street. This types of scenarios that are added are more relevant, and fluid when looked as the whole picture.
Reflections
Working with a node-based program feels exciting to me, almost like piecing together a puzzle. The flexibility of using various custom nodes opens up many possibilities, and I’m particularly interested in exploring those that can enhance text prompts. Balancing these different parameters requires careful fine-tuning, and I've realized that the core of this process is designing the workflow itself.
I believe showcasing the flow and thought process behind the outcomes is just as important as the visual results. The primary focus of this project would be to design a generative structure that automates the text-to-video process—essentially simplifying the complexities of how humans write into something machines can interpret. Rather than striving for a “perfect” AI-generated result, my goal is to create visual outputs that reflect the fragmented and imperfect nature of the prompts. By embracing the flaws and unexpected elements produced by the machine, it could be a way to humanize the generative process.