
WEEK 5
CONTEXTUAlIZING TOOL
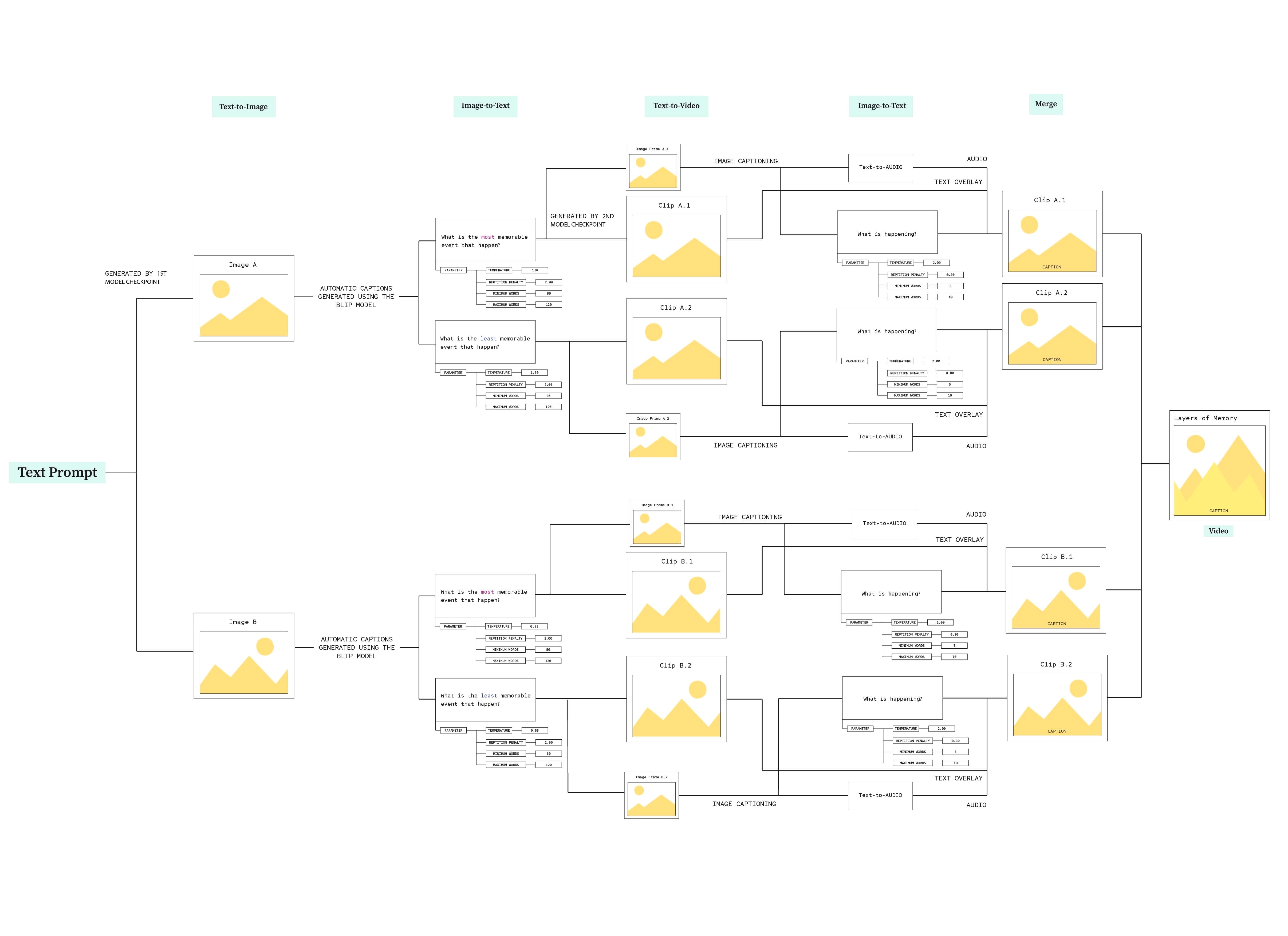
Diagram of the final workflow
Captioning Videos
Inspired by the DreamMaker, I added another layer by captioning the videos. I used another image-to-text extensions and limit the word counts with a range of 5 to 10 words. These captions are then overlayed on each of the videos that have been generated, describing each scenario that is happening in the videos.
This was just another activity that I just tried out to create a sequential video. Merging these videos into one created a longer duration as a whole as I couldn’t create longer videos due to the technical power that I currently have. Because the generation process requires a long time to generate one video (it takes at least 4-5 minutes), I had to find a solution if I wanted to make the experience of generating these outputs in live-time.


Feedbacks & Reflections
Point 1: Contextualizing
It is important to contextualize the tool: Generative AI has become increasingly accessible, and the widespread use of Stable Diffusion models has led to a fast-food-like consumption of AI-generated content. While the quality of these models can be considered advanced given their rapid development, they are far from picture-perfect. The danger of this rapid consumption is that excessive reliance on these tools can result in repetitive outcomes; it could become a threat to creativity.
Point 2: Documentation
Perhaps my project can offer an alternative creative approach by using these tools in unconventional ways, embracing these flaws as artistic narration. One suggestion I received was to integrate my workflow as part of the documentation rather than presenting only the final video outcomes. Visualizing the flow of my process could better showcase the values and meaningful decisions behind my workflow, such as the questions I asked during the image-to-text generation process. Given the number of technical terms and techniques involved, I also need to find a more effective way to visually represent these elements when explaining my project.
Point 3: Possible Interactions
To enhance the project further, I aim to incorporate interactivity into the generative system. One approach could involve allowing users to adjust parameters or modify parts of the prompt in real time, influencing the visual outcomes directly. Another possibility is to create a branching structure where users can make choices that shape the narrative or visual direction. Additionally, I am considering integrating sensor-based interactions, where physical movement could influence the generated visuals. Alternatively, designing an interface that reveals the layered steps behind each generated frame could help viewers engage more deeply with the process itself rather than just seeing videos as the final outcomes.
The only problem that I have at the moment is the computational power. The generation process requires a long duration, and this is an issue if I plan on creating an interactive experience, where people could also generate their own outputs. I need to find a solution to this issues and find a way to visually represent the processes behind my workflows.
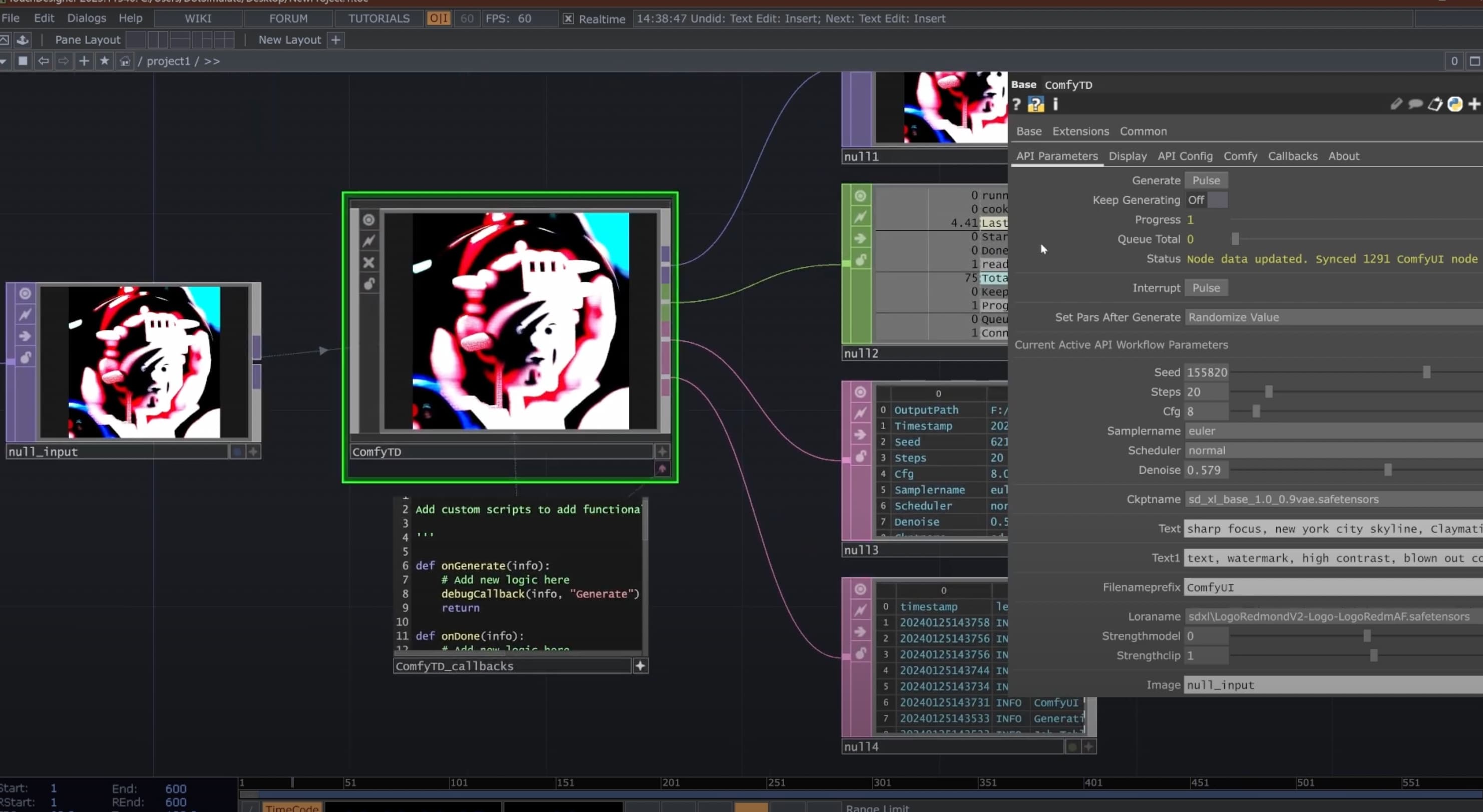
ComfyTD Operator by DotSimulate
Next Steps
I am going to try integrating my workflows to TouchDesigner interface. I saw this guide tutorial from Interactive Immersive HQ, and an artist from the AI Community built a custom base operator that allows to connect TouchDesigner with ComfyUI through API Integration.
By integrating the workflow to TouchDesigner, I could also incorporate interactions such as using a webcam for motion interactions or build an audio-visual experience using TD parameters. I also read that the operator system could control the queue time, which would be beneficial for the long generation problem I currently have.